
Cumu definisce un sistema di guida autonoma end-to-end?
A definizione più cumuna hè chì un sistema "end-to-end" hè un sistema chì inserisce l'infurmazioni di sensori prima è emette direttamente variabili di preoccupazione per u compitu. Per esempiu, in u ricunniscenza di l'imaghjini, CNN pò esse chjamatu "end-to-end" cumparatu cù u metudu tradiziunale di funzione + classificatore.
In i travaglii di guida autònuma, i dati da parechji sensori (cum'è camere, LiDAR, Radar, o IMU ...) sò input, è i segnali di cuntrollu di u veiculu (cum'è l'acceleratore o l'angolo di u volante) sò direttamente emessi. Per cunsiderà i prublemi di adattazione di diversi mudelli di veiculi, l'output pò ancu esse rilassatu à a trajectoria di guida di u veiculu.
Basatu annantu à sta fundazione, sò ancu emersi cuncetti modulari end-to-end, cum'è UniAD, chì migliurà u rendiment intruducendu a supervisione di i travaglii intermedi pertinenti, in più di i segnali finali di cuntrollu di output o waypoints. Tuttavia, da una definizione cusì stretta, l'essenza di end-to-end deve esse a trasmissione senza perdita di l'infurmazioni sensoriali.
Fighjemu prima l'interfacce trà i moduli sensori è PnC in sistemi non-end-to-end. Di solitu, detectemu l'uggetti in lista bianca (cum'è vitture, persone, etc.) è analizà è predice e so proprietà. Amparamu ancu di l'ambiente staticu (cum'è a struttura di a strada, i limiti di velocità, i semafori, etc.). S'è no fussemu più detallati, avemu ancu detectà ostaculi universali. In cortu, l'infurmazioni prudutte da queste percepzioni custituiscenu un mudellu di visualizazione di sceni di guida cumplessi.
In ogni casu, per certi sceni assai evidenti, l'astrazione esplicita attuale ùn pò micca descriverà cumplettamente i fatturi chì affettanu u cumpurtamentu di guida in a scena, o i travaglii chì avemu bisognu di definisce sò troppu triviali, è hè difficiule di enumerate tutti i travaglii richiesti. Per quessa, i sistemi end-to-end furniscenu una (forse implicitamente) una rapprisintazioni cumpleta cù a speranza di agisce automaticamente è senza perdita nantu à PnC cù questa informazione. In u mo parè, tutti i sistemi chì ponu scuntrà stu requisitu pò esse chjamatu generalizatu end-to-end.
In quantu à l'altri prublemi, cum'è alcune ottimisazioni di scenarii d'interazzione dinamica, crede chì almenu micca solu l'end-to-end ponu risolve questi prublemi, è l'end-to-end pò esse micca a megliu suluzione. I metudi tradiziunali ponu risolve questi prublemi, è di sicuru, quandu a quantità di dati hè abbastanza grande, end-to-end pò furnisce una suluzione megliu.
Certi malintesi nantu à a guida autonoma end-to-end
1. Segnali di cuntrollu è waypoints deve esse uscita à esse end-to-end.
Sè vo site d'accordu cù u cuncettu largu di punta à punta discutitu sopra, allura stu prublema hè faciule da capisce. End-to-end duverebbe enfatizà a trasmissione senza perdita di l'infurmazioni piuttostu cà direttamente u voluminu di u travagliu. Un accostu strettu di punta à punta pruvucarà assai prublemi innecessarii è necessitanu assai suluzioni segrete per assicurà a sicurità.
2.U sistema end-to-end deve esse basatu nantu à mudelli grandi o visione pura.
Ùn ci hè micca una cunnessione necessaria trà a guida autonoma end-to-end, a guida autonoma di grande mudellu, è a guida autonoma puramente visuale perchè sò cuncetti completamente indipendenti; un sistema end-to-end ùn hè micca necessariamente guidatu da grandi mudelli, nè hè necessariamente guidatu da a visione pura. di.
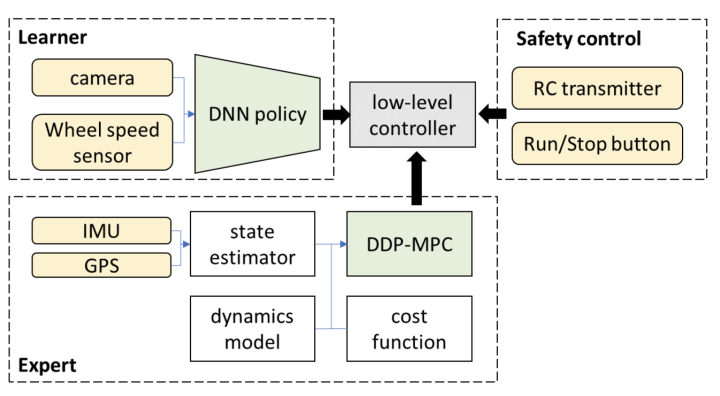
3.À longu andà, hè pussibule per u sistema end-to-end sopra-mintuatu in un sensu ristrettu per ottene una guida autònoma sopra u livellu L3?
A prestazione di ciò chì hè attualmente chjamatu pura FSD end-to-end hè luntanu da abbastanza per scuntrà l'affidabilità è a stabilità necessaria à u livellu L3. Per dissi di più, s'è u sistemu self-driving voli esse accettatu da u publicu, a chjave hè s'ellu u publicu pò accettà chì in certi casi, a macchina hà da fà i sbagli, è l'omu pò facirmenti scioglie. Questu hè più difficiuli per un sistema puro end-to-end.
Per esempiu, Waymo è Cruise in l'America di u Nordu anu avutu assai accidenti. In ogni casu, l'ultimu accidentu di Cruise hà risultatu in dui feriti, ancu s'è tali accidenti sò abbastanza inevitabbili è accettabili per i cunduttori umani. Tuttavia, dopu à stu accidente, u sistema misjudged u locu di l'accidentu è u locu di i feriti è downgraded à u modu pull-over, pruvucannu i feriti à esse trascinatu per un bellu pezzu. Stu cumpurtamentu hè inaccettabile per qualsiasi cunduttore umanu normale. Ùn serà micca fattu, è i risultati seranu assai cattivi.
Inoltre, questu hè una sveglia chì duvemu cunsiderà currettamente cumu evità sta situazione durante u sviluppu è u funziunamentu di sistemi di guida autònuma.
4.Allora in questu mumentu, chì sò i suluzioni pratichi per a prossima generazione di sistemi di guida assistita in massa?
Sicondu a mo capiscitura attuale, quandu si usa u chjamatu mudellu end-to-end in a guida, dopu avè uscita a trajectoria, torna una suluzione basatu nantu à i metudi tradiziunali. In alternativa, i pianificatori basati nantu à l'apprendimentu è l'algoritmi tradiziunali di pianificazione di a traiettoria generanu più traiettorie simultaneamente è poi selezziunate una trajectoria attraversu un selettore.
Stu tipu di suluzione secreta è scelta limita u limitu superiore di u rendiment di stu sistema in cascata se questa architettura di sistema hè aduttatu. Se stu metudu hè sempre basatu annantu à l'apprendimentu di feedback puri, i fallimenti imprevisibles saranu è l'ughjettu di esse sicuru ùn serà micca rializatu in tuttu.
Se avemu cunsideratu re-optimizing o selezziunà cù i metudi di pianificazione tradiziunali nantu à questa trajectoria di output, questu hè equivalente à a trajectoria prodotta da u metudu guidatu da l'apprendimentu; dunque, perchè ùn avemu micca direttamente ottimisimu è cercate sta trajectoria?
Di sicuru, certi pirsuni dicenu chì un tali ottimisazione o prublema di ricerca ùn hè micca cunvessu, hà un grande spaziu statale, è hè impussibile di eseguisce in tempu reale nantu à un sistema in-vehicle. Imploru tutti à cunsiderà attentamente sta quistione: In l'ultimi deci anni, u sistema di percepzioni hà ricevutu almenu centu volte u dividendu di a putenza di computing, ma chì hè u nostru modulu PnC?
S'ellu permette ancu à u modulu PnC d'utilizà una grande putenza di computing, cumminata cù qualchi avanzati in l'algoritmi di ottimisazione avanzati in l'ultimi anni, sta cunclusione hè sempre curretta? Per stu tipu di prublema, duvemu cunsiderà ciò chì hè currettu da i primi principii.
5.How à cunciliari la rilazioni trà dati-driven è i metudi tradiziunali?
Ghjucà à scacchi hè un esempiu assai simili à a guida autònoma. In u ferraghju di questu annu, Deepmind hà publicatu un articulu chjamatu "Grandmaster-Level Chess Without Search", discutendu s'ellu hè fattibile di utilizà solu data-driven è abbandunà a ricerca MCTS in AlphaGo è AlphaZero. Simile à a guida autònoma, una sola rete hè aduprata per l'azzioni di output direttamente, mentre chì tutti i passi successivi sò ignorati.
L'articulu cuncludi chì, malgradu quantità considerablei di dati è paràmetri di mudelli, i risultati abbastanza ragiunate ponu esse ottenuti senza aduprà una ricerca. Tuttavia, ci sò differenzi significativi cumparatu cù i metudi chì utilizanu a ricerca. Questu hè soprattuttu utile per trattà cun alcuni endgames cumplessi.
Per scenarii cumplessi o casi d'angle chì necessitanu ghjochi multi-passu, sta analogia rende sempre difficiule di abbandunà completamente l'ottimisazione tradiziunale o l'algoritmi di ricerca. Utilizendu ragiunate i vantaghji di diverse tecnulugia cum'è AlphaZero hè u megliu modu per migliurà u rendiment.

6.Metudu tradiziunale = basatu in regula si altri?
Aghju avutu à curregà stu cuncettu una volta è più volte mentre parlava cù parechje persone. Parechje persone crèdenu chì, finu à chì ùn hè micca puramente guidatu da dati, ùn hè micca basatu in regula. Per esempiu, in i scacchi, a memorizazione di e formule è i registri di scacchi per memoria hè basatu nantu à regule, ma cum'è AlphaGo è AlphaZero, dà à u mudellu a capacità di esse raziunale per ottimisazione è ricerca. Ùn pensu micca chì si pò esse chjamatu basatu in regule.
Per via di questu, u grande mudellu stessu hè attualmente mancatu, è i circadori cercanu di furnisce un mudellu di apprendimentu per mezu di metudi cum'è CoT. Tuttavia, à u cuntrariu di i travaglii chì necessitanu ricunniscenza di l'imaghjini puramente basati in dati è motivi inspiegabili, ogni azzione di una persona chì conduce hà una forza motrice chjara.
Sottu u disignu di l'architettura di l'algoritmu appropritatu, a traiettoria di decisione deve esse variabile è esse uniformemente ottimisata sottu a guida di scopi scientifichi, piuttostu cà a forza di patching è aghjustà i paràmetri per riparà diversi casi. Un tali sistema naturalmente ùn hà micca tutti i tipi di regule strane codificate.
Cunclusioni
In corta, end-to-end pò esse una strada tecnicu prometente, ma cumu u cuncettu hè applicatu richiede più ricerca. Pensu chì una mansa di dati è paràmetri di mudellu ùn hè micca l'unica suluzione curretta, è se vulemu superà l'altri, avemu da cuntinuà à travaglià dura.
Postu tempu: Apr-24-2024