
Hvordan defineres et end-to-end autonomt køresystem?
Den mest almindelige definition er, at et "ende-til-ende"-system er et system, der indlæser rå sensorinformation og direkte udsender variabler af interesse for opgaven. For eksempel kan CNN i billedgenkendelse kaldes "end-to-end" sammenlignet med den traditionelle feature + classifier-metode.
Ved autonome kørselsopgaver indlæses data fra forskellige sensorer (såsom kameraer, LiDAR, Radar eller IMU...), og køretøjets styresignaler (såsom gashåndtag eller ratvinkel) udsendes direkte. For at overveje tilpasningsproblemerne for forskellige køretøjsmodeller kan outputtet også lempes til køretøjets kørebane.
Baseret på dette grundlag er der også opstået modulære end-to-end koncepter, såsom UniAD, som forbedrer ydeevnen ved at indføre overvågning af relevante mellemliggende opgaver, udover de endelige output kontrolsignaler eller waypoints. Men ud fra en så snæver definition burde essensen af ende-til-ende være den tabsfri overførsel af sensorisk information.
Lad os først gennemgå grænsefladerne mellem sensing- og PnC-moduler i ikke-ende-til-ende-systemer. Normalt opdager vi hvidlistede objekter (såsom biler, mennesker osv.) og analyserer og forudsiger deres egenskaber. Vi lærer også om det statiske miljø (såsom vejstruktur, hastighedsgrænser, trafiklys osv.). Hvis vi var mere detaljerede, ville vi også opdage universelle forhindringer. Kort sagt udgør informationsoutputtet af disse opfattelser en visningsmodel af komplekse kørescener.
Men for nogle meget åbenlyse scener kan den nuværende eksplicitte abstraktion ikke fuldt ud beskrive de faktorer, der påvirker køreadfærden i scenen, eller de opgaver, vi skal definere, er for trivielle, og det er svært at opregne alle nødvendige opgaver. Derfor giver end-to-end-systemer en (måske implicit) omfattende repræsentation med håbet om automatisk og tabsfrit at handle på PnC'er med denne information. Efter min mening kan alle systemer, der kan opfylde dette krav, kaldes generaliserede end-to-end.
Hvad angår andre problemer, såsom nogle optimeringer af dynamiske interaktionsscenarier, tror jeg, at i det mindste ikke kun ende-til-ende kan løse disse problemer, og ende-til-ende er måske ikke den bedste løsning. Traditionelle metoder kan løse disse problemer, og selvfølgelig, når mængden af data er stor nok, kan ende-til-ende give en bedre løsning.
Nogle misforståelser om ende-til-ende autonom kørsel
1. Styresignaler og waypoints skal udsendes for at være ende-til-ende.
Hvis du er enig i det brede ende-til-ende-koncept diskuteret ovenfor, så er dette problem let at forstå. End-to-end bør lægge vægt på tabsfri transmission af information i stedet for direkte at outputte opgavevolumen. En snæver ende-til-ende tilgang vil forårsage en masse unødvendige problemer og kræve en masse skjulte løsninger for at sikre sikkerheden.
2. End-to-end-systemet skal være baseret på store modeller eller ren vision.
Der er ingen nødvendig sammenhæng mellem ende-til-ende autonom kørsel, autonom kørsel med store modeller og rent visuel autonom kørsel, fordi de er helt uafhængige begreber; et ende-til-ende-system er ikke nødvendigvis drevet af store modeller, og det er heller ikke nødvendigvis drevet af ren vision. af.
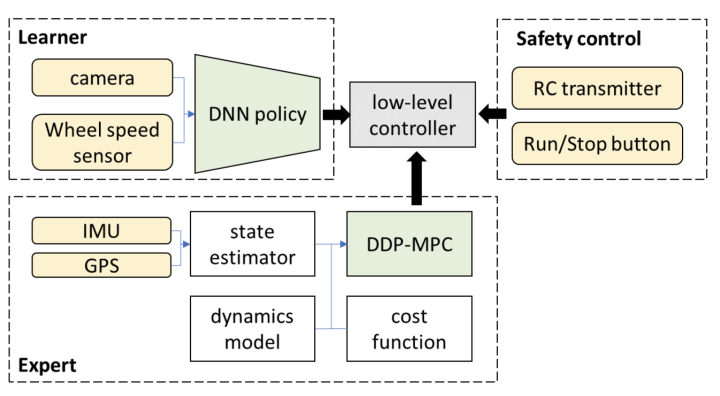
3.Er det på sigt muligt for ovennævnte ende-til-ende-system i snæver forstand at opnå autonom kørsel over L3-niveauet?
Ydeevnen af det, der i øjeblikket kaldes ren end-to-end FSD, er langt fra tilstrækkelig til at opfylde den pålidelighed og stabilitet, der kræves på L3-niveau. For at sige det mere ligeud, hvis det selvkørende system ønsker at blive accepteret af offentligheden, er det centrale, om offentligheden kan acceptere, at maskinen i nogle tilfælde vil begå fejl, og mennesker kan nemt løse dem. Dette er sværere for et rent ende-til-ende-system.
For eksempel har både Waymo og Cruise i Nordamerika haft mange ulykker. Cruises sidste ulykke resulterede dog i to skader, selvom sådanne ulykker er ret uundgåelige og acceptable for menneskelige chauffører. Men efter denne ulykke fejlbedømte systemet ulykkesstedet og de tilskadekomnes placering og nedjusterede til pull-over-tilstand, hvilket medførte, at de tilskadekomne blev slæbt i lang tid. Denne adfærd er uacceptabel for enhver normal chauffør. Det bliver ikke gjort, og resultaterne vil være meget dårlige.
Desuden er dette et wake-up call, at vi nøje bør overveje, hvordan vi undgår denne situation under udvikling og drift af autonome køresystemer.
4.Hvad er så i øjeblikket de praktiske løsninger for den næste generation af masseproducerede assisterede køresystemer?
Efter min nuværende forståelse vil det, når man bruger den såkaldte end-to-end model i kørsel, efter at have outputtet banen, returnere en løsning baseret på traditionelle metoder. Alternativt udsender læringsbaserede planlæggere og traditionelle baneplanlægningsalgoritmer flere baner samtidigt og vælger derefter en bane gennem en vælger.
Denne form for skjult løsning og valg begrænser den øvre grænse for ydeevnen af dette kaskadesystem, hvis denne systemarkitektur er vedtaget. Hvis denne metode stadig er baseret på ren feedback-læring, vil der opstå uforudsigelige fejl, og målet om at være sikker vil slet ikke blive nået.
Hvis vi overvejer at genoptimere eller udvælge ved hjælp af traditionelle planlægningsmetoder på denne outputbane, svarer dette til den bane, der produceres af den læringsdrevne metode; hvorfor optimerer og søger vi derfor ikke direkte på denne bane?
Selvfølgelig vil nogle mennesker sige, at et sådant optimerings- eller søgeproblem er ikke-konveks, har et stort tilstandsrum og er umuligt at køre i realtid på et system i køretøjet. Jeg bønfalder alle om nøje at overveje dette spørgsmål: I de sidste ti år har perceptionssystemet modtaget mindst hundrede gange så meget udbytte af computerkraft, men hvad med vores PnC-modul?
Hvis vi også tillader PnC-modulet at bruge stor computerkraft, kombineret med nogle fremskridt inden for avancerede optimeringsalgoritmer i de senere år, er denne konklusion så stadig korrekt? For denne type problemer bør vi overveje, hvad der er korrekt ud fra de første principper.
5.Hvordan forene forholdet mellem datadrevne og traditionelle metoder?
At spille skak er et eksempel, der ligner autonom kørsel. I februar i år udgav Deepmind en artikel kaldet "Grandmaster-Level Chess Without Search", der diskuterede, om det er muligt kun at bruge datadrevet og opgive MCTS-søgning i AlphaGo og AlphaZero. I lighed med autonom kørsel bruges kun ét netværk til direkte at udlæse handlinger, mens alle efterfølgende trin ignoreres.
Artiklen konkluderer, at der på trods af betydelige mængder af data og modelparametre kan opnås ret rimelige resultater uden at bruge en søgning. Der er dog betydelige forskelle i forhold til metoder, der bruger søgning. Dette er især nyttigt til at håndtere nogle komplekse slutspil.
For komplekse scenarier eller hjørnesager, der kræver spil i flere trin, gør denne analogi det stadig vanskeligt helt at opgive traditionelle optimerings- eller søgealgoritmer. Rimelig udnyttelse af fordelene ved forskellige teknologier som AlphaZero er den bedste måde at forbedre ydeevnen på.

6.Traditionel metode = regelbaseret hvis andet?
Jeg har været nødt til at rette dette koncept igen og igen, mens jeg har talt med mange mennesker. Mange mennesker tror, at så længe det ikke er rent datadrevet, er det ikke regelbaseret. I skak er det eksempelvis regelbaseret at huske formler og skakrekorder udenad, men ligesom AlphaGo og AlphaZero giver det modellen mulighed for at være rationel gennem optimering og søgning. Jeg synes ikke, det kan kaldes regelbaseret.
På grund af dette mangler selve den store model i øjeblikket, og forskere forsøger at give en læringsdrevet model gennem metoder som CoT. Men i modsætning til opgaver, der kræver ren datadrevet billedgenkendelse og uforklarlige årsager, har enhver handling af en person, der kører, en klar drivkraft.
Under det passende algoritmearkitekturdesign bør beslutningsforløbet blive variabelt og være ensartet optimeret under vejledning af videnskabelige mål i stedet for at tvangslappe og justere parametre for at løse forskellige tilfælde. Sådan et system har naturligvis ikke alle slags hårdtkodede mærkelige regler.
Konklusion
Kort sagt kan ende-til-ende være en lovende teknisk vej, men hvordan konceptet anvendes kræver mere forskning. Jeg tror, at en masse data og modelparametre ikke er den eneste rigtige løsning, og hvis vi vil overgå andre, skal vi blive ved med at arbejde hårdt.
Indlægstid: 24-apr-2024