
Πώς να ορίσετε ένα σύστημα αυτόνομης οδήγησης από άκρο σε άκρο;
Ο πιο συνηθισμένος ορισμός είναι ότι ένα σύστημα "από άκρο σε άκρο" είναι ένα σύστημα που εισάγει ακατέργαστες πληροφορίες αισθητήρα και εξάγει απευθείας μεταβλητές που αφορούν την εργασία. Για παράδειγμα, στην αναγνώριση εικόνας, το CNN μπορεί να ονομαστεί "από άκρο σε άκρο" σε σύγκριση με την παραδοσιακή μέθοδο χαρακτηριστικών + ταξινομητή.
Στις εργασίες αυτόνομης οδήγησης, δεδομένα από διάφορους αισθητήρες (όπως κάμερες, LiDAR, Radar ή IMU...) εισάγονται και σήματα ελέγχου του οχήματος (όπως η γωνία του γκαζιού ή του τιμονιού) εξάγονται απευθείας. Για να ληφθούν υπόψη τα ζητήματα προσαρμογής διαφορετικών μοντέλων οχημάτων, η έξοδος μπορεί επίσης να χαλαρώσει στην τροχιά οδήγησης του οχήματος.
Με βάση αυτό το θεμέλιο, έχουν επίσης προκύψει αρθρωτές έννοιες από άκρο σε άκρο, όπως το UniAD, που βελτιώνουν την απόδοση εισάγοντας την επίβλεψη των σχετικών ενδιάμεσων εργασιών, επιπλέον των τελικών σημάτων ελέγχου εξόδου ή των σημείων διαδρομής. Ωστόσο, από έναν τόσο στενό ορισμό, η ουσία του από άκρο σε άκρο θα πρέπει να είναι η μετάδοση αισθητηριακών πληροφοριών χωρίς απώλειες.
Ας εξετάσουμε πρώτα τις διεπαφές μεταξύ των μονάδων ανίχνευσης και PnC σε μη-άκρο σε άκρο συστήματα. Συνήθως, εντοπίζουμε αντικείμενα στη λίστα επιτρεπόμενων (όπως αυτοκίνητα, άτομα κ.λπ.) και αναλύουμε και προβλέπουμε τις ιδιότητές τους. Μαθαίνουμε επίσης για το στατικό περιβάλλον (όπως η δομή του δρόμου, τα όρια ταχύτητας, τα φανάρια κ.λπ.). Αν ήμασταν πιο λεπτομερείς, θα εντοπίζαμε και καθολικά εμπόδια. Εν ολίγοις, η εξαγωγή πληροφοριών από αυτές τις αντιλήψεις αποτελεί ένα μοντέλο απεικόνισης πολύπλοκων σκηνών οδήγησης.
Ωστόσο, για ορισμένες πολύ προφανείς σκηνές, η τρέχουσα ρητή αφαίρεση δεν μπορεί να περιγράψει πλήρως τους παράγοντες που επηρεάζουν την οδηγική συμπεριφορά στη σκηνή ή οι εργασίες που πρέπει να ορίσουμε είναι πολύ ασήμαντες και είναι δύσκολο να απαριθμήσουμε όλες τις απαιτούμενες εργασίες. Επομένως, τα συστήματα από άκρο σε άκρο παρέχουν μια (ίσως σιωπηρά) ολοκληρωμένη αναπαράσταση με την ελπίδα να ενεργούν αυτόματα και χωρίς απώλειες στα PnC με αυτές τις πληροφορίες. Κατά τη γνώμη μου, όλα τα συστήματα που μπορούν να ικανοποιήσουν αυτήν την απαίτηση μπορούν να ονομαστούν γενικευμένα από άκρο σε άκρο.
Όσον αφορά άλλα ζητήματα, όπως ορισμένες βελτιστοποιήσεις σεναρίων δυναμικής αλληλεπίδρασης, πιστεύω ότι τουλάχιστον όχι μόνο από άκρο σε άκρο μπορεί να λύσει αυτά τα προβλήματα, και το από άκρο σε άκρο μπορεί να μην είναι η καλύτερη λύση. Οι παραδοσιακές μέθοδοι μπορούν να λύσουν αυτά τα προβλήματα, και φυσικά, όταν ο όγκος των δεδομένων είναι αρκετά μεγάλος, το end-to-end μπορεί να προσφέρει καλύτερη λύση.
Μερικές παρεξηγήσεις σχετικά με την αυτόνομη οδήγηση από άκρο σε άκρο
1. Τα σήματα ελέγχου και τα σημεία διαδρομής πρέπει να εξάγονται για να είναι από άκρο σε άκρο.
Εάν συμφωνείτε με την ευρεία έννοια από άκρο σε άκρο που συζητήθηκε παραπάνω, τότε αυτό το πρόβλημα είναι εύκολο να κατανοηθεί. Από άκρο σε άκρο θα πρέπει να δίνει έμφαση στη μετάδοση πληροφοριών χωρίς απώλειες αντί στην απευθείας έξοδο του όγκου εργασιών. Μια στενή προσέγγιση από άκρο σε άκρο θα προκαλέσει πολλά περιττά προβλήματα και θα απαιτήσει πολλές κρυφές λύσεις για την εξασφάλιση της ασφάλειας.
2.Το σύστημα από άκρο σε άκρο πρέπει να βασίζεται σε μεγάλα μοντέλα ή καθαρή όραση.
Δεν υπάρχει απαραίτητη σύνδεση μεταξύ της αυτόνομης οδήγησης από άκρο σε άκρο, της αυτόνομης οδήγησης μεγάλου μοντέλου και της καθαρά οπτικής αυτόνομης οδήγησης, επειδή είναι εντελώς ανεξάρτητες έννοιες. ένα σύστημα από άκρο σε άκρο δεν οδηγείται απαραίτητα από μεγάλα μοντέλα, ούτε κατευθύνεται απαραίτητα από καθαρή όραση. του.
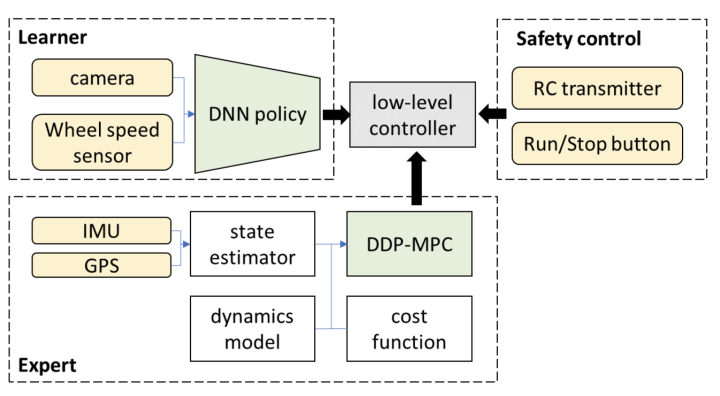
3.Μακροπρόθεσμα, είναι δυνατόν το προαναφερθέν σύστημα end-to-end με στενή έννοια να επιτύχει αυτόνομη οδήγηση πάνω από το επίπεδο L3;
Η απόδοση αυτού που σήμερα ονομάζεται καθαρή FSD από άκρο σε άκρο απέχει πολύ από το να είναι επαρκής για να καλύψει την αξιοπιστία και τη σταθερότητα που απαιτούνται στο επίπεδο L3. Για να το πούμε πιο ωμά, εάν το σύστημα αυτόνομης οδήγησης θέλει να γίνει αποδεκτό από το κοινό, το κλειδί είναι εάν το κοινό μπορεί να αποδεχθεί ότι σε ορισμένες περιπτώσεις, το μηχάνημα θα κάνει λάθη και οι άνθρωποι μπορούν εύκολα να τα λύσουν. Αυτό είναι πιο δύσκολο για ένα καθαρό σύστημα end-to-end.
Για παράδειγμα, τόσο η Waymo όσο και η Cruise στη Βόρεια Αμερική είχαν πολλά ατυχήματα. Ωστόσο, το τελευταίο ατύχημα του Cruise είχε ως αποτέλεσμα δύο τραυματισμούς, αν και τέτοια ατυχήματα είναι αρκετά αναπόφευκτα και αποδεκτά για τους ανθρώπους οδηγούς. Ωστόσο, μετά από αυτό το ατύχημα, το σύστημα εκτίμησε εσφαλμένα την τοποθεσία του ατυχήματος και τη θέση του τραυματία και υποβάθμισε τη λειτουργία pull-over, με αποτέλεσμα ο τραυματίας να σύρεται για μεγάλο χρονικό διάστημα. Αυτή η συμπεριφορά είναι απαράδεκτη για κάθε κανονικό οδηγό. Δεν θα γίνει, και τα αποτελέσματα θα είναι πολύ άσχημα.
Επιπλέον, αυτή είναι μια κλήση αφύπνισης που θα πρέπει να εξετάσουμε προσεκτικά πώς να αποφύγουμε αυτή την κατάσταση κατά την ανάπτυξη και λειτουργία συστημάτων αυτόνομης οδήγησης.
4. Αυτή τη στιγμή, λοιπόν, ποιες είναι οι πρακτικές λύσεις για την επόμενη γενιά συστημάτων υποβοηθούμενης οδήγησης μαζικής παραγωγής;
Σύμφωνα με την τρέχουσα κατανόησή μου, όταν χρησιμοποιείτε το λεγόμενο μοντέλο από άκρο σε άκρο στην οδήγηση, μετά την έξοδο της τροχιάς, θα επιστρέψει μια λύση που βασίζεται σε παραδοσιακές μεθόδους. Εναλλακτικά, οι σχεδιαστές που βασίζονται στη μάθηση και οι παραδοσιακοί αλγόριθμοι σχεδιασμού τροχιάς εξάγουν πολλαπλές τροχιές ταυτόχρονα και στη συνέχεια επιλέγουν μία τροχιά μέσω ενός επιλογέα.
Αυτό το είδος κρυφής λύσης και επιλογής περιορίζει το ανώτατο όριο απόδοσης αυτού του συστήματος καταρράκτη εάν υιοθετηθεί αυτή η αρχιτεκτονική συστήματος. Εάν αυτή η μέθοδος εξακολουθεί να βασίζεται στην καθαρή μάθηση με ανατροφοδότηση, θα προκύψουν απρόβλεπτες αποτυχίες και ο στόχος της ασφάλειας δεν θα επιτευχθεί καθόλου.
Αν σκεφτούμε την εκ νέου βελτιστοποίηση ή την επιλογή χρησιμοποιώντας παραδοσιακές μεθόδους προγραμματισμού σε αυτήν την τροχιά εξόδου, αυτό ισοδυναμεί με την τροχιά που παράγεται από τη μέθοδο που βασίζεται στη μάθηση. Επομένως, γιατί δεν βελτιστοποιούμε άμεσα και δεν αναζητούμε αυτήν την τροχιά;
Φυσικά, μερικοί άνθρωποι θα έλεγαν ότι ένα τέτοιο πρόβλημα βελτιστοποίησης ή αναζήτησης είναι μη κυρτό, έχει μεγάλο χώρο κατάστασης και είναι αδύνατο να εκτελεστεί σε πραγματικό χρόνο σε ένα σύστημα εντός του οχήματος. Παρακαλώ όλους να εξετάσουν προσεκτικά αυτό το ερώτημα: Τα τελευταία δέκα χρόνια, το σύστημα αντίληψης έχει λάβει τουλάχιστον εκατό φορές το μέρισμα υπολογιστικής ισχύος, αλλά τι γίνεται με την ενότητα PnC;
Εάν επιτρέψουμε επίσης στη μονάδα PnC να χρησιμοποιεί μεγάλη υπολογιστική ισχύ, σε συνδυασμό με ορισμένες προόδους στους προηγμένους αλγόριθμους βελτιστοποίησης τα τελευταία χρόνια, εξακολουθεί να είναι σωστό αυτό το συμπέρασμα; Για αυτού του είδους το πρόβλημα, θα πρέπει να εξετάσουμε τι είναι σωστό από τις πρώτες αρχές.
5. Πώς να συμφιλιωθεί η σχέση μεταξύ μεθόδων που βασίζονται σε δεδομένα και παραδοσιακών μεθόδων;
Το να παίζεις σκάκι είναι ένα παράδειγμα πολύ παρόμοιο με την αυτόνομη οδήγηση. Τον Φεβρουάριο του τρέχοντος έτους, η Deepmind δημοσίευσε ένα άρθρο με τίτλο "Grandmaster-Level Chess Without Search", συζητώντας εάν είναι εφικτό να χρησιμοποιηθεί μόνο βάσει δεδομένων και να εγκαταλειφθεί η αναζήτηση MCTS στο AlphaGo και το AlphaZero. Παρόμοια με την αυτόνομη οδήγηση, μόνο ένα δίκτυο χρησιμοποιείται για την άμεση έξοδο ενεργειών, ενώ όλα τα επόμενα βήματα αγνοούνται.
Το άρθρο καταλήγει στο συμπέρασμα ότι, παρά τις σημαντικές ποσότητες δεδομένων και παραμέτρων μοντέλου, μπορούν να ληφθούν αρκετά λογικά αποτελέσματα χωρίς τη χρήση αναζήτησης. Ωστόσο, υπάρχουν σημαντικές διαφορές σε σύγκριση με τις μεθόδους που χρησιμοποιούν αναζήτηση. Αυτό είναι ιδιαίτερα χρήσιμο για την αντιμετώπιση ορισμένων πολύπλοκων τελικών παιχνιδιών.
Για πολύπλοκα σενάρια ή γωνιακές περιπτώσεις που απαιτούν παιχνίδια πολλαπλών βημάτων, αυτή η αναλογία εξακολουθεί να δυσκολεύει την πλήρη εγκατάλειψη των παραδοσιακών αλγορίθμων βελτιστοποίησης ή αναζήτησης. Η εύλογη χρήση των πλεονεκτημάτων διαφόρων τεχνολογιών όπως το AlphaZero είναι ο καλύτερος τρόπος για τη βελτίωση της απόδοσης.

6.Παραδοσιακή μέθοδος = βασισμένη σε κανόνες;
Χρειάστηκε να διορθώσω αυτή την ιδέα ξανά και ξανά ενώ μιλούσα με πολλούς ανθρώπους. Πολλοί άνθρωποι πιστεύουν ότι εφόσον δεν βασίζεται αποκλειστικά σε δεδομένα, δεν βασίζεται σε κανόνες. Για παράδειγμα, στο σκάκι, η απομνημόνευση τύπων και σκακιστικών ρεκόρ με βάση τους κανόνες βασίζεται σε κανόνες, αλλά όπως το AlphaGo και το AlphaZero, δίνει στο μοντέλο τη δυνατότητα να είναι ορθολογικό μέσω βελτιστοποίησης και αναζήτησης. Δεν νομίζω ότι μπορεί να ονομαστεί βάσει κανόνων.
Εξαιτίας αυτού, το ίδιο το μεγάλο μοντέλο λείπει επί του παρόντος και οι ερευνητές προσπαθούν να παράσχουν ένα μοντέλο που βασίζεται στη μάθηση μέσω μεθόδων όπως η CoT. Ωστόσο, σε αντίθεση με τις εργασίες που απαιτούν καθαρή αναγνώριση εικόνας βάσει δεδομένων και ανεξήγητους λόγους, κάθε ενέργεια ενός ατόμου που οδηγεί έχει μια σαφή κινητήρια δύναμη.
Κάτω από την κατάλληλη σχεδίαση αρχιτεκτονικής αλγορίθμου, η τροχιά απόφασης θα πρέπει να μεταβάλλεται και να βελτιστοποιείται ομοιόμορφα υπό την καθοδήγηση επιστημονικών στόχων, αντί να επιδιορθώνει και να προσαρμόζει τις παραμέτρους για να διορθώνει διαφορετικές περιπτώσεις. Ένα τέτοιο σύστημα φυσικά δεν έχει κάθε είδους σκληρά κωδικοποιημένους περίεργους κανόνες.
Σύναψη
Εν ολίγοις, το end-to-end μπορεί να είναι μια πολλά υποσχόμενη τεχνική διαδρομή, αλλά το πώς εφαρμόζεται η ιδέα απαιτεί περισσότερη έρευνα. Νομίζω ότι μια δέσμη δεδομένων και παραμέτρων μοντέλου δεν είναι η μόνη σωστή λύση και αν θέλουμε να ξεπεράσουμε τους άλλους, πρέπει να συνεχίσουμε να εργαζόμαστε σκληρά.
Ώρα δημοσίευσης: Απρ-24-2024