
Kiel difini fin-al-finan aŭtonomian vetursistemon?
La plej ofta difino estas ke "fin-al-fina" sistemo estas sistemo kiu enigas krudajn sensilinformojn kaj rekte eligas variablojn de maltrankvilo al la tasko. Ekzemple, en bildrekono, CNN povas esti nomita "fin-al-fina" kompare kun la tradicia trajto + klasigilo metodo.
En aŭtonomiaj veturaj taskoj, datenoj de diversaj sensiloj (kiel fotiloj, LiDAR, Radaro aŭ IMU...) estas enigataj, kaj veturilaj kontrolsignaloj (kiel akcelilo aŭ stirilangulo) estas rekte eligitaj. Por pripensi la adaptadtemojn de malsamaj veturilmodeloj, la produktaĵo ankaŭ povas esti malstreĉita al la veturtrajektorio de la veturilo.
Surbaze de ĉi tiu fundamento, ankaŭ aperis modulaj fin-al-finaj konceptoj, kiel UniAD, kiuj plibonigas agadon per enkonduko de superrigardo de rilataj mezaj taskoj, krom la finaj eligo-kontrolsignaloj aŭ vojpunktoj. Tamen, de tia malvasta difino, la esenco de fin-al-fina devus esti la senperda dissendo de sensaj informoj.
Ni unue reviziu la interfacojn inter sentado kaj PnC-moduloj en ne-fin-al-finaj sistemoj. Kutime, ni detektas blanklistigitajn objektojn (kiel aŭtojn, homojn, ktp.) kaj analizas kaj antaŭdiras iliajn trajtojn. Ni ankaŭ lernas pri la statika medio (kiel vojstrukturo, rapidlimoj, trafiklumoj, ktp.). Se ni estus pli detalaj, ni ankaŭ detektus universalajn obstaklojn. Mallonge, la informproduktado de tiuj perceptoj konsistigas ekranmodelon de kompleksaj veturscenoj.
Tamen, por kelkaj tre evidentaj scenoj, la nuna eksplicita abstraktado ne povas plene priskribi la faktorojn kiuj influas veturkonduton en la sceno, aŭ la taskoj ni devas difini estas tro bagatelaj, kaj estas malfacile listigi ĉiujn postulatajn taskojn. Tial, fin-al-finaj sistemoj disponigas (eble implicite) ampleksan reprezenton kun la espero aŭtomate kaj senperde agado al PnCs kun ĉi tiu informo. Laŭ mi, ĉiuj sistemoj, kiuj povas plenumi ĉi tiun postulon, povas esti nomataj ĝeneraligitaj fin-al-finaj.
Koncerne aliajn aferojn, kiel iuj optimumigoj de dinamikaj interagaj scenaroj, mi kredas, ke almenaŭ ne nur fin-al-fina povas solvi ĉi tiujn problemojn, kaj fino-al-fina eble ne estas la plej bona solvo. Tradiciaj metodoj povas solvi ĉi tiujn problemojn, kaj kompreneble, kiam la kvanto da datumoj estas sufiĉe granda, fino al fino povas provizi pli bonan solvon.
Kelkaj miskomprenoj pri fin-al-fina aŭtonomia veturado
1. Kontrolaj signaloj kaj vojpunktoj devas esti eligitaj por esti fin-al-finaj.
Se vi konsentas kun la larĝa fino-al-fina koncepto diskutita supre, tiam ĉi tiu problemo estas facile komprenebla. Fin-al-fina devus emfazi la senperdan dissendon de informoj prefere ol rekte eligi la taskvolumenon. Mallarĝa aliro al fino kaŭzos multajn nenecesajn problemojn kaj postulos multajn sekretajn solvojn por certigi sekurecon.
2.La fin-al-fina sistemo devas baziĝi sur grandaj modeloj aŭ pura vizio.
Ne estas necesa ligo inter fin-al-fina aŭtonomia veturado, grandmodela aŭtonomia veturado, kaj pure vida aŭtonoma veturado ĉar ili estas tute sendependaj konceptoj; fin-al-fina sistemo ne estas nepre movita de grandaj modeloj, nek ĝi estas nepre movita de pura vizio. de.
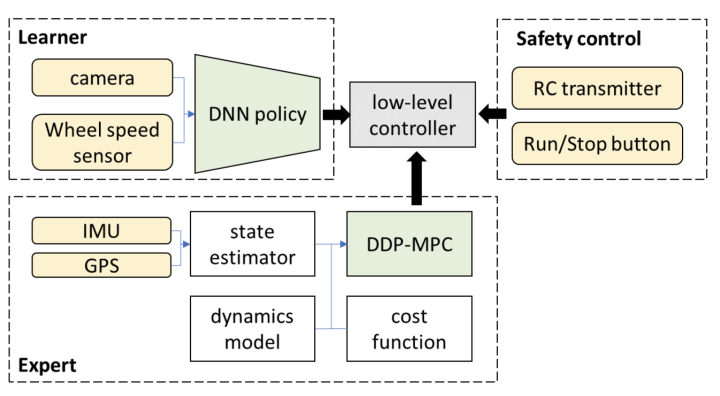
3.Longtempe, ĉu eblas, ke la supre menciita sistemo fin-al-fina en malvasta senco atingi aŭtonoman veturadon super la L3-nivelo?
La agado de tio, kio estas nuntempe nomata pura fin-al-fina FSD, estas malproksima de sufiĉa por renkonti la fidindecon kaj stabilecon postulatajn ĉe la L3-nivelo. Por diri pli malklare, se la memvetura sistemo volas esti akceptita de la publiko, la ŝlosilo estas ĉu la publiko povas akcepti, ke en iuj kazoj, la maŝino faros erarojn, kaj homoj facile povas solvi ilin. Ĉi tio estas pli malfacila por pura fin-al-fina sistemo.
Ekzemple, kaj Waymo kaj Cruise en Nordameriko havis multajn akcidentojn. Tamen, la lasta akcidento de Cruise rezultigis du vundojn, kvankam tiaj akcidentoj estas sufiĉe neeviteblaj kaj akcepteblaj por homaj ŝoforoj. Tamen, post ĉi tiu akcidento, la sistemo misjuĝis la lokon de la akcidento kaj la lokon de la vunditoj kaj malaltigis al pullover-reĝimo, igante la vunditojn esti trenitaj dum longa tempo. Ĉi tiu konduto estas neakceptebla por iu normala homa ŝoforo. Ĝi ne estos farita, kaj la rezultoj estos tre malbonaj.
Krome, ĉi tio estas vekvoko, kiun ni zorge pripensu kiel eviti ĉi tiun situacion dum la disvolviĝo kaj funkciado de aŭtonomaj kondukaj sistemoj.
4.Do en ĉi tiu momento, kiaj estas la praktikaj solvoj por la venonta generacio de amasproduktitaj helpa vetursistemoj?
Laŭ mia nuna kompreno, kiam oni uzas la tiel nomatan fin-al-finan modelon en veturado, post eligo de la trajektorio, ĝi redonos solvon bazitan sur tradiciaj metodoj. Alternative, lern-bazitaj planistoj kaj tradiciaj trajektoraj planadalgoritmoj eligas multoblajn trajektorojn samtempe kaj tiam elektas unu trajektorion tra elektilo.
Tiu speco de kaŝa solvo kaj elekto limigas la supran limon de la efikeco de tiu kaskadsistemo se tiu sistema arkitekturo estas adoptita. Se ĉi tiu metodo ankoraŭ baziĝas sur pura reago-lernado, neantaŭvideblaj fiaskoj okazos kaj la celo esti sekura tute ne estos atingita.
Se ni pripensas re-optimumigi aŭ elekti uzante tradiciajn planajn metodojn sur ĉi tiu produktaĵtrajektorio, tio estas ekvivalenta al la trajektorio produktita per la lernad-movita metodo; tial, kial ni ne rekte optimumigas kaj serĉu ĉi tiun trajektorion?
Kompreneble, iuj homoj dirus, ke tia optimumigo aŭ serĉa problemo estas ne-konveksa, havas grandan ŝtatan spacon, kaj estas neeble funkcii en reala tempo sur en-veturilo sistemo. Mi petegas ĉiujn zorge pripensi ĉi tiun demandon: En la pasintaj dek jaroj, la perceptsistemo ricevis almenaŭ centoble la dividendon de komputika potenco, sed kio pri nia PnC-modulo?
Se ni ankaŭ permesas al la modulo PnC uzi grandan komputikan potencon, kombinitan kun iuj progresoj en altnivelaj optimumigo-algoritmoj en la lastaj jaroj, ĉu ĉi tiu konkludo ankoraŭ estas ĝusta? Por ĉi tiu speco de problemo, ni devus konsideri kio estas ĝusta de unuaj principoj.
5.Kiel akordigi la rilaton inter datumaj kaj tradiciaj metodoj?
Ŝakludado estas ekzemplo tre simila al aŭtonoma veturado. En februaro de ĉi tiu jaro, Deepmind publikigis artikolon nomitan "Grandmaster-Level Chess Without Search", diskutante ĉu estas fareble uzi nur datuman veturadon kaj forlasi MCTS-serĉon en AlphaGo kaj AlphaZero. Simila al aŭtonomia veturado, nur unu reto estas uzata por rekte eligi agojn, dum ĉiuj postaj paŝoj estas ignoritaj.
La artikolo konkludas, ke malgraŭ konsiderindaj kvantoj da datumoj kaj modelaj parametroj, sufiĉe akcepteblaj rezultoj povas esti akiritaj sen uzi serĉon. Tamen, estas gravaj diferencoj kompare al metodoj uzantaj serĉon. Ĉi tio estas precipe utila por trakti iujn kompleksajn finludojn.
Por kompleksaj scenaroj aŭ angulaj kazoj, kiuj postulas plurpaŝajn ludojn, ĉi tiu analogio ankoraŭ malfaciligas tute forlasi tradiciajn optimumigojn aŭ serĉalgoritmojn. Racie utiligi la avantaĝojn de diversaj teknologioj kiel AlphaZero estas la plej bona maniero plibonigi rendimenton.

6.Tradicia metodo = regulbazita se alie?
Mi devis korekti ĉi tiun koncepton ree kaj ree dum parolado kun multaj homoj. Multaj homoj kredas, ke tiel longe kiel ĝi ne estas pure datuma, ĝi ne estas regulbazita. Ekzemple, en ŝako, enmemorigi formulojn kaj ŝakrekordojn laŭmemore estas regul-bazita, sed kiel AlphaGo kaj AlphaZero, ĝi donas al la modelo la kapablon esti racia per optimumigo kaj serĉo. Mi ne pensas, ke ĝi povas esti nomata regulbaza.
Pro tio, la granda modelo mem nuntempe mankas, kaj esploristoj provas disponigi lernan-movitan modelon per metodoj kiel ekzemple CoT. Tamen, male al taskoj kiuj postulas puran datuman bildrekonon kaj neklarigeblajn kialojn, ĉiu ago de persono veturanta havas klaran movan forton.
Sub la taŭga algoritmo-arkitekturo-dezajno, la decida trajektorio devus iĝi varia kaj esti unuforme optimumigita sub la gvidado de sciencaj celoj, prefere ol perforte fliki kaj alĝustigi parametrojn por ripari malsamajn kazojn. Tia sistemo nature ne havas ĉiajn malmolajn strangajn regulojn.
Konkludo
Mallonge, fin-al-fina povas esti promesplena teknika vojo, sed kiel la koncepto estas aplikata postulas pli da esplorado. Mi pensas, ke amaso da datumoj kaj modelaj parametroj ne estas la sola ĝusta solvo, kaj se ni volas superi aliajn, ni devas daŭre labori forte.
Afiŝtempo: Apr-24-2024