
¿Cómo definir un sistema de conducción autónomo de extremo a extremo?
La definición más común es que un sistema "de un extremo a otro" es un sistema que ingresa información sin procesar del sensor y genera directamente variables de interés para la tarea. Por ejemplo, en el reconocimiento de imágenes, CNN se puede llamar "de un extremo a otro" en comparación con el método tradicional de característica + clasificador.
En las tareas de conducción autónoma, se introducen datos de varios sensores (como cámaras, LiDAR, radar o IMU...) y se emiten directamente señales de control del vehículo (como el acelerador o el ángulo del volante). Para considerar las cuestiones de adaptación de diferentes modelos de vehículos, la salida también puede adaptarse a la trayectoria de conducción del vehículo.
Sobre esta base, también han surgido conceptos modulares de extremo a extremo, como UniAD, que mejoran el rendimiento al introducir la supervisión de tareas intermedias relevantes, además de las señales de control de salida final o puntos de referencia. Sin embargo, según una definición tan estrecha, la esencia de un extremo a otro debería ser la transmisión sin pérdidas de información sensorial.
Primero revisemos las interfaces entre los módulos de detección y PnC en sistemas que no son de un extremo a otro. Por lo general, detectamos objetos incluidos en la lista blanca (como automóviles, personas, etc.) y analizamos y predecimos sus propiedades. También aprendemos sobre el entorno estático (como la estructura de la carretera, los límites de velocidad, los semáforos, etc.). Si fuéramos más detallados, también detectaríamos obstáculos universales. En resumen, la información generada por estas percepciones constituye un modelo de visualización de escenas de conducción complejas.
Sin embargo, para algunas escenas muy obvias, la abstracción explícita actual no puede describir completamente los factores que afectan el comportamiento de conducción en la escena, o las tareas que debemos definir son demasiado triviales y es difícil enumerar todas las tareas requeridas. Por lo tanto, los sistemas de extremo a extremo proporcionan una representación integral (quizás implícitamente) con la esperanza de actuar de forma automática y sin pérdidas sobre los PnC con esta información. En mi opinión, todos los sistemas que pueden cumplir con este requisito pueden denominarse generalizados de extremo a extremo.
En cuanto a otros problemas, como algunas optimizaciones de escenarios de interacción dinámica, creo que al menos no solo de un extremo a otro pueden resolver estos problemas, y es posible que de un extremo a otro no sea la mejor solución. Los métodos tradicionales pueden resolver estos problemas y, por supuesto, cuando la cantidad de datos es lo suficientemente grande, el extremo a extremo puede proporcionar una mejor solución.
Algunos malentendidos sobre la conducción autónoma de extremo a extremo
1. Las señales de control y los puntos de referencia deben emitirse de un extremo a otro.
Si está de acuerdo con el concepto amplio de extremo a extremo discutido anteriormente, entonces este problema es fácil de entender. De un extremo a otro debe enfatizarse la transmisión de información sin pérdidas en lugar de generar directamente el volumen de la tarea. Un enfoque estrecho de extremo a extremo causará muchos problemas innecesarios y requerirá muchas soluciones encubiertas para garantizar la seguridad.
2.El sistema de extremo a extremo debe basarse en modelos grandes o visión pura.
No existe una conexión necesaria entre la conducción autónoma de extremo a extremo, la conducción autónoma de modelos grandes y la conducción autónoma puramente visual porque son conceptos completamente independientes; un sistema de extremo a extremo no está necesariamente impulsado por grandes modelos, ni necesariamente por una visión pura. de.
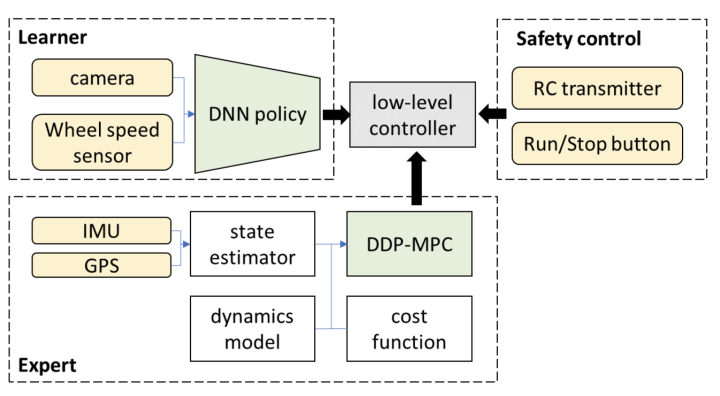
3.A largo plazo, ¿es posible que el sistema integral mencionado anteriormente alcance en sentido estricto una conducción autónoma por encima del nivel L3?
El rendimiento de lo que actualmente se denomina FSD puro de extremo a extremo está lejos de ser suficiente para cumplir con la confiabilidad y estabilidad requeridas en el nivel L3. Para decirlo más claramente, si el sistema de conducción autónoma quiere ser aceptado por el público, la clave es si el público puede aceptar que, en algunos casos, la máquina cometerá errores y los humanos pueden resolverlos fácilmente. Esto es más difícil para un sistema puro de extremo a extremo.
Por ejemplo, tanto Waymo como Cruise en Norteamérica han tenido muchos accidentes. Sin embargo, el último accidente de Cruise provocó dos heridos, aunque este tipo de accidentes son bastante inevitables y aceptables para los conductores humanos. Sin embargo, después de este accidente, el sistema calculó mal la ubicación del accidente y la ubicación de los heridos y pasó al modo de parada, lo que provocó que los heridos fueran arrastrados durante mucho tiempo. Este comportamiento es inaceptable para cualquier conductor humano normal. No se hará y los resultados serán muy malos.
Además, esta es una llamada de atención de que debemos considerar cuidadosamente cómo evitar esta situación durante el desarrollo y funcionamiento de los sistemas de conducción autónoma.
4. Entonces, ¿cuáles son en este momento las soluciones prácticas para la próxima generación de sistemas de conducción asistida producidos en masa?
Según mi entendimiento actual, cuando se utiliza el llamado modelo de extremo a extremo en la conducción, después de generar la trayectoria, se devolverá una solución basada en métodos tradicionales. Alternativamente, los planificadores basados en el aprendizaje y los algoritmos tradicionales de planificación de trayectorias generan múltiples trayectorias simultáneamente y luego seleccionan una trayectoria a través de un selector.
Este tipo de solución y elección encubierta limita el límite superior del rendimiento de este sistema en cascada si se adopta esta arquitectura del sistema. Si este método todavía se basa en el aprendizaje puro por retroalimentación, se producirán fallas impredecibles y el objetivo de estar seguro no se logrará en absoluto.
Si consideramos reoptimizar o seleccionar utilizando métodos de planificación tradicionales en esta trayectoria de producción, esto es equivalente a la trayectoria producida por el método impulsado por el aprendizaje; entonces, ¿por qué no optimizamos y buscamos directamente esta trayectoria?
Por supuesto, algunas personas dirían que dicho problema de optimización o búsqueda no es convexo, tiene un gran espacio de estado y es imposible ejecutarlo en tiempo real en un sistema de vehículo. Les imploro a todos que consideren cuidadosamente esta pregunta: en los últimos diez años, el sistema de percepción ha recibido al menos cien veces el dividendo de potencia de cálculo, pero ¿qué pasa con nuestro módulo PnC?
Si también permitimos que el módulo PnC utilice una gran potencia informática, combinado con algunos avances en algoritmos de optimización avanzados en los últimos años, ¿sigue siendo correcta esta conclusión? Para este tipo de problema, debemos considerar lo que es correcto desde los primeros principios.
5.¿Cómo conciliar la relación entre los métodos tradicionales y los basados en datos?
Jugar al ajedrez es un ejemplo muy parecido a la conducción autónoma. En febrero de este año, Deepmind publicó un artículo llamado "Ajedrez a nivel de gran maestro sin búsqueda", en el que se analiza si es factible utilizar únicamente la búsqueda MCTS basada en datos y abandonarla en AlphaGo y AlphaZero. De manera similar a la conducción autónoma, solo se utiliza una red para generar acciones directamente, mientras que todos los pasos posteriores se ignoran.
El artículo concluye que, a pesar de cantidades considerables de datos y parámetros del modelo, se pueden obtener resultados bastante razonables sin utilizar una búsqueda. Sin embargo, existen diferencias significativas en comparación con los métodos que utilizan la búsqueda. Esto es especialmente útil para lidiar con algunos finales complejos.
Para escenarios complejos o casos de esquina que requieren juegos de varios pasos, esta analogía aún hace que sea difícil abandonar por completo los algoritmos tradicionales de optimización o búsqueda. Utilizar razonablemente las ventajas de diversas tecnologías como AlphaZero es la mejor manera de mejorar el rendimiento.

6.Método tradicional = basado en reglas, ¿si no?
He tenido que corregir este concepto una y otra vez mientras hablaba con mucha gente. Mucha gente cree que mientras no se base exclusivamente en datos, no se basa en reglas. Por ejemplo, en el ajedrez, la memorización de fórmulas y registros de ajedrez de memoria se basa en reglas, pero al igual que AlphaGo y AlphaZero, le da al modelo la capacidad de ser racional mediante la optimización y la búsqueda. No creo que se pueda llamar basado en reglas.
Debido a esto, actualmente falta el modelo grande y los investigadores están tratando de proporcionar un modelo impulsado por el aprendizaje a través de métodos como CoT. Sin embargo, a diferencia de las tareas que requieren un reconocimiento de imágenes basado exclusivamente en datos y por razones inexplicables, cada acción de una persona que conduce tiene una fuerza impulsora clara.
Bajo el diseño de arquitectura de algoritmo apropiado, la trayectoria de decisión debe volverse variable y optimizarse uniformemente bajo la guía de objetivos científicos, en lugar de parchear y ajustar parámetros por la fuerza para solucionar diferentes casos. Naturalmente, un sistema de este tipo no tiene todo tipo de reglas extrañas codificadas.
Conclusión
En resumen, de extremo a extremo puede ser una ruta técnica prometedora, pero cómo se aplica el concepto requiere más investigación. Creo que un montón de datos y parámetros de modelo no es la única solución correcta, y si queremos superar a otras, tenemos que seguir trabajando duro.
Hora de publicación: 24 de abril de 2024