
چگونه یک سیستم رانندگی خودکار سرتاسر تعریف کنیم؟
متداول ترین تعریف این است که یک سیستم "انتهای به انتها" سیستمی است که اطلاعات حسگر خام را وارد می کند و مستقیماً متغیرهای مربوط به کار را خروجی می دهد. به عنوان مثال، در تشخیص تصویر، CNN را می توان در مقایسه با روش سنتی ویژگی + طبقه بندی کننده، "انتخاب به انتها" نامید.
در وظایف رانندگی خودمختار، دادههای حسگرهای مختلف (مانند دوربینها، LiDAR، رادار یا IMU...) ورودی هستند و سیگنالهای کنترل خودرو (مانند دریچه گاز یا زاویه فرمان) مستقیماً خروجی میشوند. برای در نظر گرفتن مسائل مربوط به انطباق مدل های مختلف خودرو، خروجی نیز می تواند به مسیر رانندگی خودرو کاهش یابد.
بر اساس این مبنا، مفاهیم پایان به انتها مدولار نیز پدیدار شده است، مانند UniAD، که با معرفی نظارت بر وظایف میانی مربوطه، علاوه بر سیگنال های کنترل خروجی نهایی یا ایستگاه های بین راه، عملکرد را بهبود می بخشد. با این حال، از چنین تعریف محدودی، جوهر انتها به انتها باید انتقال بدون تلفات اطلاعات حسی باشد.
اجازه دهید ابتدا رابط های بین حسگر و ماژول های PnC را در سیستم های غیر انتها به انتها مرور کنیم. معمولاً اشیاء در لیست سفید (مانند اتومبیل، افراد و غیره) را شناسایی کرده و خواص آنها را تجزیه و تحلیل و پیش بینی می کنیم. همچنین در مورد محیط استاتیک (مانند ساختار جاده، محدودیت سرعت، چراغ راهنمایی و غیره) یاد می گیریم. اگر جزئیات بیشتری داشتیم، موانع جهانی را نیز تشخیص می دادیم. به طور خلاصه، اطلاعات خروجی توسط این ادراکات، مدل نمایش صحنه های پیچیده رانندگی را تشکیل می دهد.
با این حال، برای برخی از صحنههای بسیار واضح، انتزاع صریح فعلی نمیتواند به طور کامل عواملی را که بر رفتار رانندگی در صحنه تأثیر میگذارند، توصیف کند، یا وظایفی که باید تعریف کنیم بسیار پیش پا افتاده هستند، و شمارش همه وظایف مورد نیاز دشوار است. بنابراین، سیستمهای انتها به انتها یک نمایش (شاید به طور ضمنی) جامع با این امید که به طور خودکار و بدون ضرر روی PnCها با این اطلاعات عمل کنند، ارائه میکنند. به نظر من، تمام سیستم هایی که می توانند این نیاز را برآورده کنند را می توان تعمیم یافته end-to-end نامید.
در مورد مسائل دیگر، مانند برخی بهینهسازیهای سناریوهای تعامل پویا، من معتقدم که حداقل نه تنها انتها به انتها میتواند این مشکلات را حل کند، و انتها به انتها ممکن است بهترین راهحل نباشد. روشهای سنتی میتوانند این مشکلات را حل کنند و البته زمانی که حجم دادهها به اندازه کافی زیاد باشد، ممکن است از انتها به انتها راهحل بهتری ارائه شود.
برخی سوء تفاهم ها در مورد رانندگی خودکار سرتاسر
1. سیگنال های کنترل و ایستگاه های بین راه باید خروجی باشند تا سرتاسر باشند.
اگر با مفهوم گسترده پایان به انتها مورد بحث در بالا موافق هستید، درک این مشکل آسان است. انتها به انتها باید بر انتقال بدون تلفات اطلاعات به جای خروجی مستقیم حجم کار تأکید کند. یک رویکرد محدود از انتها به انتها باعث ایجاد مشکلات غیرضروری زیادی می شود و برای اطمینان از ایمنی به راه حل های پنهان زیادی نیاز دارد.
2. سیستم end-to-end باید بر اساس مدل های بزرگ یا دید خالص باشد.
هیچ ارتباط ضروری بین رانندگی خودکار سرتاسر، رانندگی خودکار مدل بزرگ و رانندگی مستقل بصری وجود ندارد زیرا آنها مفاهیم کاملاً مستقلی هستند. یک سیستم انتها به انتها لزوماً توسط مدل های بزرگ هدایت نمی شود، و نه لزوماً توسط دید خالص هدایت می شود. از
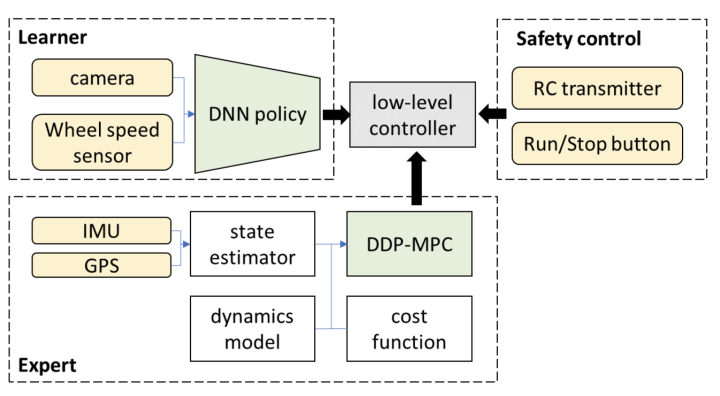
3. در درازمدت، آیا سیستم انتها به انتها ذکر شده در بالا به معنای محدود امکان رانندگی خودکار بالاتر از سطح L3 را دارد؟
عملکرد آنچه که در حال حاضر FSD خالص پایان به انتها نامیده می شود، برای برآورده کردن قابلیت اطمینان و پایداری مورد نیاز در سطح L3 کافی نیست. به بیان صریح تر، اگر سیستم خودران بخواهد مورد پذیرش عموم قرار گیرد، نکته کلیدی این است که آیا عموم مردم می توانند بپذیرند که در برخی موارد، دستگاه اشتباه می کند و انسان ها به راحتی می توانند آنها را حل کنند. این برای یک سیستم خالص به انتها دشوارتر است.
به عنوان مثال، Waymo و Cruise در آمریکای شمالی تصادفات زیادی داشته اند. با این حال، آخرین تصادف کروز منجر به دو مصدوم شد، اگرچه چنین تصادفاتی برای رانندگان انسانی کاملاً اجتناب ناپذیر و قابل قبول است. اما پس از این حادثه، سیستم محل حادثه و محل مصدوم را اشتباه ارزیابی کرده و به حالت pull-over تنزل داده و باعث کشیده شدن مصدوم برای مدت طولانی شده است. این رفتار برای هیچ راننده انسانی عادی غیرقابل قبول است. انجام نخواهد شد و نتایج بسیار بدی خواهد بود.
علاوه بر این، این زنگ هشداری است که ما باید به دقت بررسی کنیم که چگونه از این وضعیت در طول توسعه و عملکرد سیستم های رانندگی خودران جلوگیری کنیم.
4. بنابراین در حال حاضر، راه حل های عملی برای نسل بعدی سیستم های کمک رانندگی تولید انبوه چیست؟
با توجه به درک فعلی من، هنگام استفاده از مدل به اصطلاح end-to-end در رانندگی، پس از خروجی مسیر، یک راه حل مبتنی بر روش های سنتی را برمی گرداند. روش دیگر، برنامهریزان مبتنی بر یادگیری و الگوریتمهای برنامهریزی مسیر سنتی چندین مسیر را به طور همزمان خروجی میدهند و سپس یک مسیر را از طریق یک انتخابگر انتخاب میکنند.
این نوع راه حل و انتخاب پنهان، در صورت اتخاذ این معماری سیستم، حد بالایی عملکرد این سیستم آبشاری را محدود می کند. اگر این روش همچنان مبتنی بر یادگیری بازخورد خالص باشد، شکست های غیرقابل پیش بینی رخ می دهد و هدف ایمن بودن به هیچ وجه محقق نمی شود.
اگر بهینه سازی مجدد یا انتخاب با استفاده از روش های برنامه ریزی سنتی را در این مسیر خروجی در نظر بگیریم، این معادل مسیری است که توسط روش یادگیری محور تولید می شود. بنابراین، چرا ما مستقیماً این مسیر را بهینه سازی و جستجو نمی کنیم؟
البته، برخی افراد میگویند که چنین مشکل بهینهسازی یا جستجو غیرمحدب است، فضای حالت بزرگی دارد و اجرای آن در زمان واقعی در یک سیستم داخل خودرو غیرممکن است. من از همه خواهش می کنم این سوال را با دقت در نظر بگیرند: در ده سال گذشته، سیستم ادراک حداقل صد برابر سود محاسباتی را دریافت کرده است، اما ماژول PnC ما چطور؟
اگر به ماژول PnC نیز اجازه دهیم که از قدرت محاسباتی زیادی همراه با برخی پیشرفتها در الگوریتمهای بهینهسازی پیشرفته در سالهای اخیر استفاده کند، آیا این نتیجهگیری هنوز درست است؟ برای این نوع مسائل باید آنچه را که از اصول اولیه صحیح است در نظر گرفت.
5. چگونه می توان رابطه بین روش های داده محور و سنتی را تطبیق داد؟
بازی شطرنج نمونه ای بسیار شبیه به رانندگی خودمختار است. در فوریه سال جاری، Deepmind مقالهای به نام «شطرنج بدون جستجو در سطح استاد بزرگ» منتشر کرد و در مورد اینکه آیا امکان استفاده از دادهمحور و کنار گذاشتن جستجوی MCTS در AlphaGo و AlphaZero وجود دارد یا خیر. مشابه رانندگی خودکار، تنها از یک شبکه برای خروجی مستقیم اقدامات استفاده می شود، در حالی که تمام مراحل بعدی نادیده گرفته می شوند.
این مقاله نتیجه میگیرد که، علیرغم مقادیر قابلتوجهی از دادهها و پارامترهای مدل، نتایج نسبتاً معقولی را میتوان بدون استفاده از جستجو به دست آورد. با این حال، تفاوت های قابل توجهی در مقایسه با روش های استفاده از جستجو وجود دارد. این به ویژه برای مقابله با برخی از پایان بازی های پیچیده مفید است.
برای سناریوهای پیچیده یا موارد گوشهای که به بازیهای چند مرحلهای نیاز دارند، این قیاس همچنان رها کردن کامل الگوریتمهای بهینهسازی سنتی یا جستجو را دشوار میکند. استفاده منطقی از مزایای فناوری های مختلف مانند AlphaZero بهترین راه برای بهبود عملکرد است.

6.روش سنتی = قانونمدار
من مجبور شدم این مفهوم را بارها و بارها در حین صحبت با افراد زیادی اصلاح کنم. بسیاری از مردم بر این باورند که تا زمانی که صرفاً مبتنی بر داده نباشد، مبتنی بر قانون نیست. به عنوان مثال، در شطرنج، به خاطر سپردن فرمول ها و رکوردهای شطرنج بر اساس قانون است، اما مانند AlphaGo و AlphaZero، به مدل توانایی منطقی بودن از طریق بهینه سازی و جستجو را می دهد. فکر نمی کنم بتوان آن را مبتنی بر قانون نامید.
به همین دلیل، خود مدل بزرگ در حال حاضر گم شده است و محققان در تلاش هستند تا از طریق روش هایی مانند CoT یک مدل یادگیری محور ارائه کنند. با این حال، بر خلاف کارهایی که نیاز به تشخیص تصویر مبتنی بر داده خالص و دلایل غیرقابل توضیح دارند، هر اقدامی که یک فرد رانندگی می کند، نیروی محرکه واضحی دارد.
تحت طراحی معماری الگوریتم مناسب، مسیر تصمیمگیری باید متغیر شود و بهطور یکنواخت تحت هدایت اهداف علمی بهینهسازی شود، نه اینکه به اجبار وصله و تنظیم پارامترها برای رفع موارد مختلف انجام شود. چنین سیستمی طبیعتاً انواع و اقسام قوانین عجیب و غریب سخت کدگذاری شده را ندارد.
نتیجه گیری
به طور خلاصه، انتها به انتها ممکن است یک مسیر فنی امیدوارکننده باشد، اما اینکه چگونه این مفهوم به کار گرفته شود، به تحقیقات بیشتری نیاز دارد. من فکر می کنم مجموعه ای از داده ها و پارامترهای مدل تنها راه حل صحیح نیست و اگر می خواهیم از دیگران پیشی بگیریم، باید سخت کار کنیم.
زمان ارسال: آوریل-24-2024