
Comment définir un système de conduite autonome de bout en bout?
La définition la plus courante est qu'un système « de bout en bout » est un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé « de bout en bout » par rapport à la méthode traditionnelle fonctionnalité + classificateur.
Dans les tâches de conduite autonome, les données de divers capteurs (tels que les caméras, LiDAR, radar ou IMU...) sont entrées et les signaux de commande du véhicule (tels que l'angle de l'accélérateur ou du volant) sont directement émis. Pour prendre en compte les problèmes d'adaptation des différents modèles de véhicules, la sortie peut également être adaptée à la trajectoire de conduite du véhicule.
Sur cette base, des concepts modulaires de bout en bout ont également vu le jour, comme UniAD, qui améliorent les performances en introduisant la supervision des tâches intermédiaires pertinentes, en plus des signaux de contrôle de sortie finaux ou des waypoints. Cependant, à partir d’une définition aussi étroite, l’essence du système de bout en bout devrait être la transmission sans perte d’informations sensorielles.
Passons d'abord en revue les interfaces entre les modules de détection et les modules PnC dans les systèmes non de bout en bout. Habituellement, nous détectons les objets sur liste blanche (tels que les voitures, les personnes, etc.) et analysons et prédisons leurs propriétés. Nous en apprenons également sur l'environnement statique (comme la structure routière, les limitations de vitesse, les feux de circulation, etc.). Si nous étions plus détaillés, nous détecterions également les obstacles universels. En bref, les informations issues de ces perceptions constituent un modèle d'affichage de scènes de conduite complexes.
Cependant, pour certaines scènes très évidentes, l'abstraction explicite actuelle ne peut pas décrire complètement les facteurs qui affectent le comportement de conduite dans la scène, ou les tâches que nous devons définir sont trop triviales et il est difficile d'énumérer toutes les tâches requises. Par conséquent, les systèmes de bout en bout fournissent une représentation complète (peut-être implicitement) avec l’espoir d’agir automatiquement et sans perte sur les PnC avec ces informations. À mon avis, tous les systèmes capables de répondre à cette exigence peuvent être qualifiés de bout en bout généralisés.
Quant à d'autres problèmes, tels que certaines optimisations de scénarios d'interaction dynamique, je pense qu'au moins non seulement de bout en bout peut résoudre ces problèmes, et que de bout en bout n'est peut-être pas la meilleure solution. Les méthodes traditionnelles peuvent résoudre ces problèmes et, bien entendu, lorsque la quantité de données est suffisamment importante, le système de bout en bout peut constituer une meilleure solution.
Quelques malentendus sur la conduite autonome de bout en bout
1. Les signaux de contrôle et les points de cheminement doivent être émis de bout en bout.
Si vous êtes d’accord avec le concept général de bout en bout évoqué ci-dessus, alors ce problème est facile à comprendre. De bout en bout devrait mettre l’accent sur la transmission d’informations sans perte plutôt que sur la sortie directe du volume de tâches. Une approche étroite de bout en bout entraînera de nombreux problèmes inutiles et nécessitera de nombreuses solutions secrètes pour garantir la sécurité.
2.Le système de bout en bout doit être basé sur de grands modèles ou une vision pure.
Il n’y a pas de lien nécessaire entre la conduite autonome de bout en bout, la conduite autonome sur grand modèle et la conduite autonome purement visuelle car ce sont des concepts complètement indépendants ; un système de bout en bout n’est pas nécessairement piloté par de grands modèles, ni nécessairement par une vision pure. de.
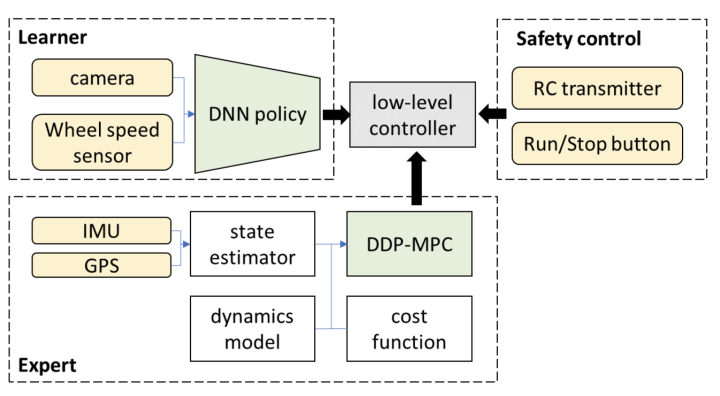
3. À long terme, est-il possible que le système de bout en bout mentionné ci-dessus, au sens strict du terme, permette une conduite autonome au-dessus du niveau L3 ?
Les performances de ce que l’on appelle actuellement FSD pur de bout en bout sont loin d’être suffisantes pour répondre à la fiabilité et à la stabilité requises au niveau L3. Pour le dire plus crûment, si le système de conduite autonome veut être accepté par le public, la clé est de savoir si le public peut accepter que dans certains cas, la machine commette des erreurs et que les humains puissent facilement les résoudre. Ceci est plus difficile pour un système pur de bout en bout.
Par exemple, Waymo et Cruise en Amérique du Nord ont eu de nombreux accidents. Cependant, le dernier accident de Cruise a fait deux blessés, bien que de tels accidents soient assez inévitables et acceptables pour les conducteurs humains. Cependant, après cet accident, le système a mal évalué l'emplacement de l'accident et l'emplacement des blessés et est passé en mode pull-over, ce qui a entraîné le traînage des blessés pendant une longue période. Ce comportement est inacceptable pour tout conducteur humain normal. Cela ne se fera pas et les résultats seront très mauvais.
En outre, il s’agit d’un signal d’alarme selon lequel nous devrions réfléchir attentivement à la manière d’éviter cette situation lors du développement et de l’exploitation des systèmes de conduite autonome.
4. Alors, à l’heure actuelle, quelles sont les solutions pratiques pour la prochaine génération de systèmes de conduite assistée produits en série ?
D'après ma compréhension actuelle, lors de l'utilisation du modèle dit de bout en bout en conduite, après avoir généré la trajectoire, il renverra une solution basée sur les méthodes traditionnelles. Alternativement, les planificateurs basés sur l'apprentissage et les algorithmes de planification de trajectoire traditionnels génèrent plusieurs trajectoires simultanément, puis sélectionnent une trajectoire via un sélecteur.
Ce type de solution et de choix cachés limite la limite supérieure des performances de ce système en cascade si cette architecture système est adoptée. Si cette méthode reste basée sur un pur apprentissage par feedback, des échecs imprévisibles se produiront et l’objectif de sécurité ne sera pas du tout atteint.
Si l’on considère la réoptimisation ou la sélection à l’aide des méthodes de planification traditionnelles sur cette trajectoire de sortie, cela équivaut à la trajectoire produite par la méthode axée sur l’apprentissage ; par conséquent, pourquoi ne pas optimiser et rechercher directement cette trajectoire ?
Bien sûr, certaines personnes diraient qu’un tel problème d’optimisation ou de recherche est non convexe, possède un grand espace d’état et est impossible à exécuter en temps réel sur un système embarqué. J'implore tout le monde de réfléchir attentivement à cette question : au cours des dix dernières années, le système de perception a reçu au moins cent fois le dividende en puissance de calcul, mais qu'en est-il de notre module PnC ?
Si nous permettons également au module PnC d’utiliser une grande puissance de calcul, combinée à certaines avancées des algorithmes d’optimisation avancés ces dernières années, cette conclusion est-elle toujours correcte ? Pour ce genre de problème, nous devons considérer ce qui est correct selon les premiers principes.
5.Comment concilier la relation entre les méthodes data-driven et traditionnelles ?
Jouer aux échecs est un exemple très similaire à la conduite autonome. En février de cette année, Deepmind a publié un article intitulé "Grandmaster-Level Chess Without Search", discutant de la possibilité d'utiliser uniquement la recherche basée sur les données et d'abandonner la recherche MCTS dans AlphaGo et AlphaZero. Semblable à la conduite autonome, un seul réseau est utilisé pour générer directement des actions, tandis que toutes les étapes ultérieures sont ignorées.
L'article conclut que, malgré des quantités considérables de données et de paramètres de modèle, des résultats assez raisonnables peuvent être obtenus sans recourir à une recherche. Il existe cependant des différences significatives par rapport aux méthodes utilisant la recherche. Ceci est particulièrement utile pour gérer certaines fins de partie complexes.
Pour les scénarios complexes ou les cas particuliers qui nécessitent des jeux en plusieurs étapes, cette analogie rend encore difficile l’abandon complet des algorithmes d’optimisation ou de recherche traditionnels. Utiliser raisonnablement les avantages de diverses technologies comme AlphaZero est le meilleur moyen d’améliorer les performances.

6.Méthode traditionnelle = basée sur des règles, sinon ?
J'ai dû corriger ce concept encore et encore en discutant avec de nombreuses personnes. Beaucoup de gens pensent que tant qu’elle n’est pas uniquement basée sur des données, elle n’est pas basée sur des règles. Par exemple, aux échecs, la mémorisation des formules et des enregistrements d'échecs par cœur est basée sur des règles, mais comme AlphaGo et AlphaZero, elle donne au modèle la capacité d'être rationnel grâce à l'optimisation et à la recherche. Je ne pense pas que cela puisse être qualifié de basé sur des règles.
Pour cette raison, le grand modèle lui-même est actuellement manquant et les chercheurs tentent de fournir un modèle axé sur l'apprentissage grâce à des méthodes telles que CoT. Cependant, contrairement aux tâches qui nécessitent une reconnaissance d’images purement basée sur des données et des raisons inexplicables, chaque action d’une personne au volant a une force motrice claire.
Dans le cadre d’une conception d’architecture d’algorithme appropriée, la trajectoire de décision devrait devenir variable et être uniformément optimisée sous la direction d’objectifs scientifiques, plutôt que de corriger et d’ajuster de force les paramètres pour résoudre différents cas. Un tel système ne comporte naturellement pas toutes sortes de règles étranges codées en dur.
Conclusion
En bref, le bout en bout peut être une voie technique prometteuse, mais la façon dont le concept est appliqué nécessite davantage de recherches. Je pense qu'un ensemble de données et de paramètres de modèle n'est pas la seule bonne solution, et si nous voulons surpasser les autres, nous devons continuer à travailler dur.
Heure de publication : 24 avril 2024