
Hoe kinne jo in end-to-end autonoom rydsysteem definiearje?
De meast foarkommende definysje is dat in "end-to-end" systeem in systeem is dat rûge sensorynformaasje ynput en direkt fariabelen fan soarch foar de taak útfiert. Bygelyks, yn ôfbyldingsherkenning kin CNN "end-to-end" wurde neamd yn ferliking mei de tradisjonele funksje + klassifikaasjemetoade.
By autonome rydtaken wurde gegevens fan ferskate sensoren (lykas kamera's, LiDAR, Radar, of IMU ...) ynfierd, en autokontrôlesignalen (lykas gas- of stjoerhoeke) wurde direkt útfierd. Om de oanpassingsproblemen fan ferskate automodellen te beskôgjen, kin de útfier ek wurde ûntspannen nei it rydtrajekt fan it auto.
Op grûn fan dizze stifting binne ek modulêre ein-oan-ein-konsepten ûntstien, lykas UniAD, dy't de prestaasjes ferbetterje troch tafersjoch op relevante tuskentaken yn te fieren, neist de definitive útfierkontrôlesignalen as waypoints. Ut sa'n smelle definysje moat de essinsje fan ein-oan-ein lykwols de ferliesleaze oerdracht fan sintúchlike ynformaasje wêze.
Lit ús earst de ynterfaces besjen tusken sensing en PnC-modules yn net-ein-oan-ein-systemen. Gewoanlik ûntdekke wy objekten op wite list (lykas auto's, minsken, ensfh.) En analysearje en foarsizze wy har eigenskippen. Wy leare ek oer de statyske omjouwing (lykas dykstruktuer, snelheidsgrinzen, ferkearsljochten, ensfh.). As wy mear detaillearre wiene, soene wy ek universele obstakels ûntdekke. Koartsein, de ynformaasjeútfier troch dizze opfettings foarmet in werjeftemodel fan komplekse rydsênes.
Foar guon heul foar de hân lizzende sênes kin de hjoeddeistige eksplisite abstraksje lykwols net de faktoaren folslein beskriuwe dy't rydgedrach yn 'e sêne beynfloedzje, of de taken dy't wy moatte definiearje binne te triviaal, en it is lestich om alle fereaske taken op te nimmen. Dêrom jouwe end-to-end systemen in (miskien ymplisyt) wiidweidige fertsjintwurdiging mei de hope om automatysk en losslessly te hanneljen op PnC's mei dizze ynformaasje. Neffens my kinne alle systemen dy't oan dizze eask foldwaan kinne wurde neamd generalisearre ein-to-ein.
Wat oare problemen oanbelanget, lykas guon optimisaasjes fan dynamyske ynteraksje-senario's, leau ik dat teminsten net allinich ein-oan-ein dizze problemen kinne oplosse, en ein-oan-ein kin net de bêste oplossing wêze. Tradysjonele metoaden kinne dizze problemen oplosse, en fansels, as de hoemannichte gegevens grut genôch is, kin ein-oan-ein in bettere oplossing leverje.
Guon misferstannen oer autonoom riden fan ein oant ein
1. Control sinjalen en waypoints moatte wurde útfierd te wêzen ein-to-ein.
As jo it iens binne mei it hjirboppe besprutsen brede ein-oan-ein konsept, dan is dit probleem maklik te begripen. Ein-to-ein moat de ferliesleaze oerdracht fan ynformaasje beklamje ynstee fan it direkt útfieren fan it taakfolum. In smelle ein-to-ein oanpak sil in soad ûnnedige problemen feroarsaakje en in protte geheime oplossingen fereaskje om feiligens te garandearjen.
2.It ein-oan-ein-systeem moat basearre wêze op grutte modellen of pure fisy.
Der is gjin needsaaklike ferbining tusken ein-to-ein autonoom riden, grut-model autonoom riden, en suver fisueel autonoom riden omdat it binne folslein ûnôfhinklike begripen; in ein-to-ein systeem wurdt net needsaaklikerwize dreaun troch grutte modellen, noch is it needsaaklikerwize dreaun troch suver fisy. fan.
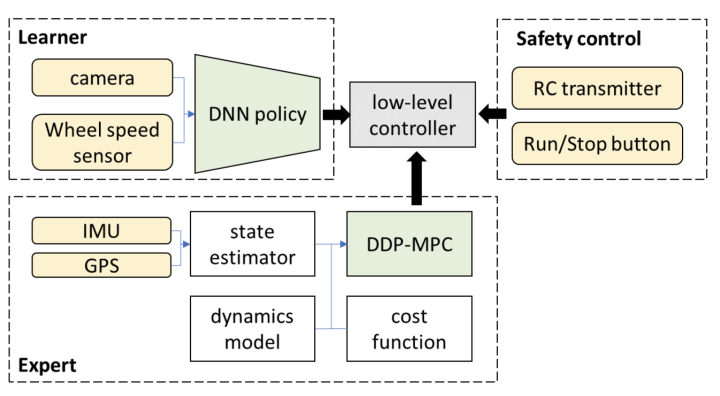
3.Is it op 'e lange termyn mooglik foar it boppeneamde ein-oan-ein-systeem yn smel sin om autonoom riden boppe it L3-nivo te berikken?
De prestaasjes fan wat op it stuit pure end-to-end FSD neamd wurdt is fier fan genôch om te foldwaan oan de betrouberens en stabiliteit dy't nedich binne op it L3-nivo. Om it krekter te sizzen, as it selsridende systeem troch it publyk akseptearre wurde wol, is de kaai oft it publyk akseptearje kin dat yn guon gefallen de masine flaters makket, en minsken kinne se maklik oplosse. Dit is dreger foar in suver ein-to-ein systeem.
Sawol Waymo as Cruise yn Noard-Amearika hawwe bygelyks in protte ûngelokken hân. It lêste ûngelok fan Cruise resultearre lykwols yn twa ferwûnings, hoewol sokke ûngelokken frij ûnûntkomber binne en akseptabel binne foar minsklike bestjoerders. Nei dit ûngelok hat it systeem lykwols de lokaasje fan it ûngelok en de lokaasje fan 'e ferwûnen ferkeard beoardiele en downgraded nei pull-over-modus, wêrtroch't de ferwûnen in lange tiid sleepten wurde. Dit gedrach is net akseptabel foar elke normale minsklike bestjoerder. It sil net dien wurde, en de resultaten sille heul min wêze.
Fierder is dit in wekker dat wy soarchfâldich moatte beskôgje hoe't jo dizze situaasje kinne foarkomme tidens de ûntwikkeling en eksploitaasje fan autonome rydsystemen.
4.Dus op dit stuit, wat binne de praktyske oplossingen foar de folgjende generaasje fan massa-produsearre assistearre rydsystemen?
Neffens myn hjoeddeistige begryp, by it brûken fan it saneamde end-to-end model yn it riden, nei it útfieren fan it trajekt, sil it in oplossing werombringe op basis fan tradisjonele metoaden. As alternatyf, lear-basearre planners en tradisjonele trajektplanningalgoritmen útfiere meardere trajekten tagelyk en selektearje dan ien trajekt troch in selector.
Dit soarte fan geheime oplossing en kar beheint de boppegrins fan 'e prestaasjes fan dit kaskadesysteem as dizze systeemarsjitektuer wurdt oannommen. As dizze metoade noch altyd basearre is op suver feedback-learen, sille ûnfoarspelbere mislearrings foarkomme en it doel fan feilich wêze sil hielendal net wurde berikt.
As wy beskôgje opnij optimalisearjen of selektearjen mei help fan tradisjonele planning metoaden op dit útfier trajekt, dit is lykweardich oan it trajekt produsearre troch de lear-oandreaune metoade; dêrom, wêrom dogge wy net direkt optimalisearjen en sykje dit trajekt?
Fansels soene guon minsken sizze dat sa'n optimisaasje- of sykprobleem net-konvex is, in grutte steatromte hat, en is ûnmooglik om yn realtime te rinnen op in systeem yn 'e auto. Ik smeekje elkenien om dizze fraach soarchfâldich te beskôgjen: yn 'e ôfrûne tsien jier hat it waarnimmingssysteem op syn minst hûndert kear it dividend foar rekkenkrêft krigen, mar hoe sit it mei ús PnC-module?
As wy de PnC-module ek tastean om grutte komputerkrêft te brûken, kombineare mei wat foarútgong yn avansearre optimisaasjealgoritmen yn 'e lêste jierren, is dizze konklúzje noch altyd korrekt? Foar dit soarte fan probleem moatte wy beskôgje wat is korrekt út earste prinsipes.
5.Hoe de relaasje tusken data-oandreaune en tradisjonele metoaden te fermoedsoenjen?
Skaken is in foarbyld dat tige ferlykber is mei autonoom riden. Yn febrewaris fan dit jier publisearre Deepmind in artikel mei de namme "Grandmaster-Level Chess Without Search", besprutsen oft it mooglik is om allinich gegevensoandreaune te brûken en MCTS-sykjen yn AlphaGo en AlphaZero te ferlitten. Fergelykber mei autonoom riden wurdt mar ien netwurk brûkt om aksjes direkt út te fieren, wylst alle folgjende stappen wurde negearre.
It artikel konkludearret dat, nettsjinsteande grutte hoemannichten gegevens en modelparameters, frij ridlike resultaten kinne wurde krigen sûnder in sykopdracht te brûken. D'r binne lykwols signifikante ferskillen yn ferliking mei metoaden dy't sykjen brûke. Dit is benammen nuttich foar it omgean mei guon komplekse einspultsjes.
Foar komplekse senario's of hoeke gefallen dy't mearstapsspultsjes nedich binne, makket dizze analogy it noch altyd lestich om tradisjonele optimalisaasje- of sykalgoritmen folslein te ferlitten. It ridlik gebrûk fan 'e foardielen fan ferskate technologyen lykas AlphaZero is de bêste manier om prestaasjes te ferbetterjen.

6.Traditional metoade = regel-basearre as oars?
Ik moast dit konsept hieltyd wer korrigearje wylst ik mei in protte minsken praat. In protte minsken leauwe dat salang't it net suver gegevens-oandreaune is, it net op regels basearre is. Bygelyks, yn skaken, memorisearjen fan formules en skaakrekords troch rote is regel-basearre, mar lykas AlphaGo en AlphaZero, jout it model de mooglikheid om rasjoneel te wêzen troch optimalisaasje en sykjen. Ik tink net dat it kin neamd wurde regel-basearre.
Dêrtroch ûntbrekt it grutte model sels op it stuit, en ûndersikers besykje in learend model te leverjen troch metoaden lykas CoT. Lykwols, yn tsjinstelling ta taken dy't pure data-oandreaune bylderkenning en ûnferklearbere redenen fereaskje, hat elke aksje fan in persoan dy't rydt in dúdlike driuwende krêft.
Under it passende algoritme-arsjitektuerûntwerp moat it beslútstrajekt fariabel wurde en unifoarm optimisearre wurde ûnder de begelieding fan wittenskiplike doelen, ynstee fan twang te lappen en parameters oan te passen om ferskate gefallen te reparearjen. Sa'n systeem hat fansels net allerhanne hurdkodearre frjemde regels.
Konklúzje
Koartsein, ein-to-ein kin in kânsrike technyske rûte wêze, mar hoe't it konsept wurdt tapast freget mear ûndersyk. Ik tink dat in boskje gegevens en modelparameters net de ienige juste oplossing is, en as wy oaren wolle oertreffe, moatte wy hurd wurkje.
Post tiid: Apr-24-2024