
एंड-टू-एंड स्वायत्त ड्राइविंग सिस्टम को कैसे परिभाषित करें?
सबसे आम परिभाषा यह है कि "एंड-टू-एंड" सिस्टम एक ऐसी प्रणाली है जो कच्चे सेंसर की जानकारी इनपुट करती है और कार्य के लिए चिंता के चर को सीधे आउटपुट करती है। उदाहरण के लिए, छवि पहचान में, सीएनएन को पारंपरिक फीचर + क्लासिफायर विधि की तुलना में "एंड-टू-एंड" कहा जा सकता है।
स्वायत्त ड्राइविंग कार्यों में, विभिन्न सेंसर (जैसे कैमरा, LiDAR, रडार, या IMU...) से डेटा इनपुट होता है, और वाहन नियंत्रण सिग्नल (जैसे थ्रॉटल या स्टीयरिंग व्हील कोण) सीधे आउटपुट होते हैं। विभिन्न वाहन मॉडलों के अनुकूलन मुद्दों पर विचार करने के लिए, आउटपुट को वाहन के ड्राइविंग प्रक्षेपवक्र में भी आराम दिया जा सकता है।
इस आधार पर, मॉड्यूलर एंड-टू-एंड अवधारणाएं भी उभरी हैं, जैसे कि यूएनआईएडी, जो अंतिम आउटपुट नियंत्रण सिग्नल या वेपॉइंट के अलावा, प्रासंगिक मध्यवर्ती कार्यों की निगरानी शुरू करके प्रदर्शन में सुधार करती है। हालाँकि, ऐसी संकीर्ण परिभाषा से, एंड-टू-एंड का सार संवेदी जानकारी का दोषरहित संचरण होना चाहिए।
आइए पहले हम नॉन-एंड-टू-एंड सिस्टम में सेंसिंग और पीएनसी मॉड्यूल के बीच इंटरफेस की समीक्षा करें। आमतौर पर, हम श्वेतसूची वाली वस्तुओं (जैसे कार, लोग, आदि) का पता लगाते हैं और उनके गुणों का विश्लेषण और अनुमान लगाते हैं। हम स्थिर वातावरण (जैसे सड़क संरचना, गति सीमा, ट्रैफिक लाइट आदि) के बारे में भी सीखते हैं। यदि हम अधिक विस्तृत होते, तो हम सार्वभौमिक बाधाओं का भी पता लगा लेते। संक्षेप में, इन धारणाओं द्वारा उत्पादित सूचना जटिल ड्राइविंग दृश्यों का एक प्रदर्शन मॉडल बनाती है।
हालाँकि, कुछ बहुत स्पष्ट दृश्यों के लिए, वर्तमान स्पष्ट अमूर्तता उन कारकों का पूरी तरह से वर्णन नहीं कर सकती है जो दृश्य में ड्राइविंग व्यवहार को प्रभावित करते हैं, या जिन कार्यों को हमें परिभाषित करने की आवश्यकता है वे बहुत तुच्छ हैं, और सभी आवश्यक कार्यों की गणना करना मुश्किल है। इसलिए, एंड-टू-एंड सिस्टम इस जानकारी के साथ पीएनसी पर स्वचालित रूप से और दोषरहित कार्य करने की आशा के साथ (शायद अंतर्निहित रूप से) व्यापक प्रतिनिधित्व प्रदान करते हैं। मेरी राय में, इस आवश्यकता को पूरा करने वाली सभी प्रणालियों को सामान्यीकृत एंड-टू-एंड कहा जा सकता है।
जहां तक अन्य मुद्दों का सवाल है, जैसे गतिशील इंटरैक्शन परिदृश्यों के कुछ अनुकूलन, मेरा मानना है कि कम से कम न केवल एंड-टू-एंड इन समस्याओं को हल कर सकता है, और एंड-टू-एंड सबसे अच्छा समाधान नहीं हो सकता है। पारंपरिक तरीके इन समस्याओं को हल कर सकते हैं, और निश्चित रूप से, जब डेटा की मात्रा काफी बड़ी हो, तो एंड-टू-एंड बेहतर समाधान प्रदान कर सकता है।
एंड-टू-एंड स्वायत्त ड्राइविंग के बारे में कुछ गलतफहमियाँ
1. नियंत्रण सिग्नल और वेपॉइंट को एंड-टू-एंड आउटपुट होना चाहिए।
यदि आप ऊपर चर्चा की गई व्यापक एंड-टू-एंड अवधारणा से सहमत हैं, तो इस समस्या को समझना आसान है। कार्य की मात्रा को सीधे आउटपुट करने के बजाय शुरू से अंत तक सूचना के दोषरहित प्रसारण पर जोर देना चाहिए। एक संकीर्ण अंत-से-अंत दृष्टिकोण बहुत सारी अनावश्यक परेशानी पैदा करेगा और सुरक्षा सुनिश्चित करने के लिए बहुत सारे गुप्त समाधानों की आवश्यकता होगी।
2.एंड-टू-एंड सिस्टम बड़े मॉडल या शुद्ध दृष्टि पर आधारित होना चाहिए।
एंड-टू-एंड स्वायत्त ड्राइविंग, बड़े-मॉडल स्वायत्त ड्राइविंग और पूरी तरह से दृश्य स्वायत्त ड्राइविंग के बीच कोई आवश्यक संबंध नहीं है क्योंकि वे पूरी तरह से स्वतंत्र अवधारणाएं हैं; एक अंत-से-अंत प्रणाली आवश्यक रूप से बड़े मॉडलों द्वारा संचालित नहीं होती है, न ही यह आवश्यक रूप से शुद्ध दृष्टि से संचालित होती है। का।
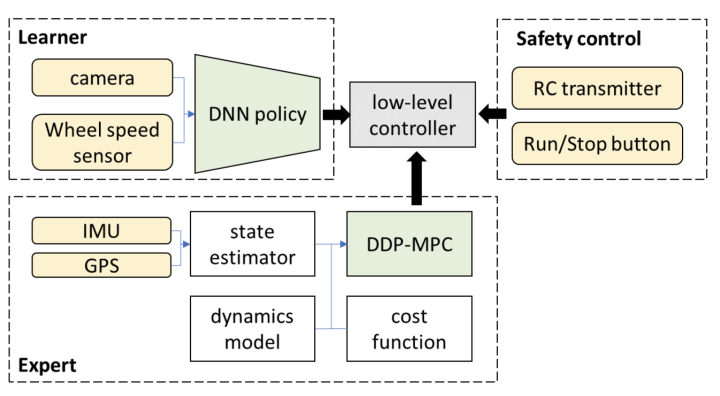
3.लंबे समय में, क्या उपरोक्त उल्लिखित एंड-टू-एंड सिस्टम के लिए L3 स्तर से ऊपर स्वायत्त ड्राइविंग हासिल करना संभव है?
जिसे वर्तमान में शुद्ध एंड-टू-एंड एफएसडी कहा जाता है उसका प्रदर्शन एल3 स्तर पर आवश्यक विश्वसनीयता और स्थिरता को पूरा करने के लिए पर्याप्त नहीं है। इसे और अधिक स्पष्ट रूप से कहने के लिए, यदि स्व-ड्राइविंग प्रणाली जनता द्वारा स्वीकार किया जाना चाहती है, तो कुंजी यह है कि क्या जनता यह स्वीकार कर सकती है कि कुछ मामलों में, मशीन गलतियाँ करेगी, और मनुष्य उन्हें आसानी से हल कर सकते हैं। शुद्ध एंड-टू-एंड सिस्टम के लिए यह अधिक कठिन है।
उदाहरण के लिए, उत्तरी अमेरिका में वेमो और क्रूज़ दोनों में कई दुर्घटनाएँ हुई हैं। हालाँकि, क्रूज़ की आखिरी दुर्घटना में दो चोटें आईं, हालाँकि ऐसी दुर्घटनाएँ मानव चालकों के लिए काफी अपरिहार्य और स्वीकार्य हैं। हालाँकि, इस दुर्घटना के बाद, सिस्टम ने दुर्घटना के स्थान और घायलों के स्थान को गलत बताया और पुल-ओवर मोड में डाउनग्रेड कर दिया, जिससे घायलों को लंबे समय तक घसीटना पड़ा। यह व्यवहार किसी भी सामान्य मानव चालक के लिए अस्वीकार्य है। ऐसा नहीं किया जाएगा और परिणाम बहुत बुरे होंगे.
इसके अलावा, यह एक चेतावनी है कि हमें सावधानीपूर्वक विचार करना चाहिए कि स्वायत्त ड्राइविंग सिस्टम के विकास और संचालन के दौरान इस स्थिति से कैसे बचा जाए।
4.तो इस समय, अगली पीढ़ी के बड़े पैमाने पर उत्पादित सहायक ड्राइविंग सिस्टम के लिए व्यावहारिक समाधान क्या हैं?
मेरी वर्तमान समझ के अनुसार, ड्राइविंग में तथाकथित एंड-टू-एंड मॉडल का उपयोग करते समय, प्रक्षेप पथ को आउटपुट करने के बाद, यह पारंपरिक तरीकों के आधार पर एक समाधान लौटाएगा। वैकल्पिक रूप से, सीखने-आधारित योजनाकार और पारंपरिक प्रक्षेप पथ योजना एल्गोरिदम एक साथ कई प्रक्षेप पथों को आउटपुट करते हैं और फिर एक चयनकर्ता के माध्यम से एक प्रक्षेप पथ का चयन करते हैं।
यदि इस सिस्टम आर्किटेक्चर को अपनाया जाता है तो इस प्रकार का गुप्त समाधान और विकल्प इस कैस्केड सिस्टम के प्रदर्शन की ऊपरी सीमा को सीमित कर देता है। यदि यह विधि अभी भी शुद्ध फीडबैक सीखने पर आधारित है, तो अप्रत्याशित विफलताएँ होंगी और सुरक्षित होने का लक्ष्य बिल्कुल भी हासिल नहीं किया जाएगा।
यदि हम इस आउटपुट प्रक्षेपवक्र पर पारंपरिक नियोजन विधियों का उपयोग करके पुन: अनुकूलन या चयन करने पर विचार करते हैं, तो यह सीखने-संचालित विधि द्वारा उत्पादित प्रक्षेपवक्र के बराबर है; इसलिए, हम इस प्रक्षेप पथ को सीधे अनुकूलित और खोज क्यों नहीं करते?
बेशक, कुछ लोग कहेंगे कि इस तरह की अनुकूलन या खोज समस्या गैर-उत्तल है, इसमें एक बड़ा राज्य स्थान है, और इन-व्हीकल सिस्टम पर वास्तविक समय में चलाना असंभव है। मैं हर किसी से इस प्रश्न पर सावधानीपूर्वक विचार करने का आग्रह करता हूं: पिछले दस वर्षों में, धारणा प्रणाली को कम से कम सौ गुना कंप्यूटिंग पावर लाभांश प्राप्त हुआ है, लेकिन हमारे पीएनसी मॉड्यूल के बारे में क्या?
यदि हम पीएनसी मॉड्यूल को हाल के वर्षों में उन्नत अनुकूलन एल्गोरिदम में कुछ प्रगति के साथ मिलकर बड़ी कंप्यूटिंग शक्ति का उपयोग करने की अनुमति देते हैं, तो क्या यह निष्कर्ष अभी भी सही है? इस प्रकार की समस्या के लिए, हमें पहले सिद्धांतों से विचार करना चाहिए कि क्या सही है।
5.डेटा-संचालित और पारंपरिक तरीकों के बीच संबंध को कैसे सुलझाएं?
शतरंज खेलना स्वायत्त ड्राइविंग के समान ही एक उदाहरण है। इस वर्ष के फरवरी में, डीपमाइंड ने "ग्रैंडमास्टर-लेवल शतरंज विदाउट सर्च" नामक एक लेख प्रकाशित किया, जिसमें चर्चा की गई कि क्या केवल डेटा-संचालित का उपयोग करना और अल्फ़ागो और अल्फ़ाज़ीरो में एमसीटीएस खोज को छोड़ना संभव है। स्वायत्त ड्राइविंग के समान, सीधे आउटपुट क्रियाओं के लिए केवल एक नेटवर्क का उपयोग किया जाता है, जबकि बाद के सभी चरणों को अनदेखा कर दिया जाता है।
लेख का निष्कर्ष है कि, पर्याप्त मात्रा में डेटा और मॉडल मापदंडों के बावजूद, खोज का उपयोग किए बिना काफी उचित परिणाम प्राप्त किए जा सकते हैं। हालाँकि, खोज का उपयोग करने वाले तरीकों की तुलना में महत्वपूर्ण अंतर हैं। यह कुछ जटिल एंडगेम से निपटने के लिए विशेष रूप से उपयोगी है।
जटिल परिदृश्यों या कोने वाले मामलों के लिए जिनमें मल्टी-स्टेप गेम की आवश्यकता होती है, यह सादृश्य अभी भी पारंपरिक अनुकूलन या खोज एल्गोरिदम को पूरी तरह से छोड़ना मुश्किल बना देता है। अल्फ़ाज़ीरो जैसी विभिन्न प्रौद्योगिकियों के लाभों का उचित उपयोग प्रदर्शन को बेहतर बनाने का सबसे अच्छा तरीका है।

6.पारंपरिक विधि=नियम आधारित, अन्यथा?
कई लोगों से बात करते समय मुझे इस अवधारणा को बार-बार सही करना पड़ा है। कई लोगों का मानना है कि जब तक यह पूरी तरह से डेटा-आधारित नहीं है, तब तक यह नियम-आधारित नहीं है। उदाहरण के लिए, शतरंज में, सूत्रों और शतरंज के रिकॉर्ड को रटना नियम-आधारित है, लेकिन अल्फ़ागो और अल्फ़ाज़ीरो की तरह, यह मॉडल को अनुकूलन और खोज के माध्यम से तर्कसंगत होने की क्षमता देता है। मुझे नहीं लगता कि इसे नियम आधारित कहा जा सकता है.
इस वजह से, बड़ा मॉडल वर्तमान में गायब है, और शोधकर्ता सीओटी जैसे तरीकों के माध्यम से एक सीखने-संचालित मॉडल प्रदान करने की कोशिश कर रहे हैं। हालाँकि, उन कार्यों के विपरीत, जिनमें शुद्ध डेटा-संचालित छवि पहचान और अस्पष्ट कारणों की आवश्यकता होती है, ड्राइविंग करने वाले व्यक्ति की प्रत्येक क्रिया में एक स्पष्ट प्रेरक शक्ति होती है।
उपयुक्त एल्गोरिदम आर्किटेक्चर डिज़ाइन के तहत, निर्णय प्रक्षेपवक्र को परिवर्तनशील होना चाहिए और विभिन्न मामलों को ठीक करने के लिए मापदंडों को जबरन पैच करने और समायोजित करने के बजाय वैज्ञानिक लक्ष्यों के मार्गदर्शन में समान रूप से अनुकूलित किया जाना चाहिए। ऐसी प्रणाली में स्वाभाविक रूप से सभी प्रकार के हार्ड-कोडित अजीब नियम नहीं होते हैं।
निष्कर्ष
संक्षेप में, शुरू से अंत तक एक आशाजनक तकनीकी मार्ग हो सकता है, लेकिन अवधारणा को कैसे लागू किया जाता है इसके लिए अधिक शोध की आवश्यकता है। मुझे लगता है कि डेटा और मॉडल मापदंडों का एक समूह ही एकमात्र सही समाधान नहीं है, और यदि हम दूसरों से आगे निकलना चाहते हैं, तो हमें कड़ी मेहनत करते रहना होगा।
पोस्ट समय: अप्रैल-24-2024