
Ինչպե՞ս սահմանել ծայրից ծայր ինքնավար վարման համակարգ:
Ամենատարածված սահմանումն այն է, որ «վերջից մինչև վերջ» համակարգը համակարգ է, որը մուտքագրում է չմշակված սենսորային տեղեկատվությունը և ուղղակիորեն դուրս է բերում առաջադրանքին վերաբերող փոփոխականները: Օրինակ՝ պատկերների ճանաչման մեջ CNN-ը կարելի է անվանել «վերջից վերջ»՝ համեմատած ավանդական հատկանիշ + դասակարգիչ մեթոդի հետ։
Ինքնավար վարորդական առաջադրանքներում տարբեր սենսորներից (օրինակ՝ տեսախցիկներից, LiDAR-ից, Ռադարից կամ IMU...) մուտքագրվում են տվյալներ, իսկ մեքենայի կառավարման ազդանշանները (օրինակ՝ շնչափողի կամ ղեկի անկյունը) ուղղակիորեն դուրս են գալիս: Մեքենաների տարբեր մոդելների հարմարվողականության խնդիրները դիտարկելու համար ելքը կարող է նաև հանգստանալ մեքենայի վարման հետագծին:
Այս հիմքի հիման վրա ի հայտ են եկել նաև մոդուլային վերջից մինչև վերջ հասկացություններ, ինչպիսին է UniAD-ը, որը բարելավում է կատարողականությունը՝ ներդնելով համապատասխան միջանկյալ առաջադրանքների վերահսկում, ի լրումն վերջնական ելքային կառավարման ազդանշանների կամ ճանապարհային կետերի: Այնուամենայնիվ, նման նեղ սահմանումից վերջից մինչև վերջ էությունը պետք է լինի զգայական տեղեկատվության անկորուստ փոխանցումը:
Եկեք նախ վերանայենք ինտերֆեյսները զգայական և PnC մոդուլների միջև ոչ ծայրից ծայր համակարգերում: Սովորաբար մենք հայտնաբերում ենք սպիտակ ցուցակում ընդգրկված առարկաներ (օրինակ՝ մեքենաներ, մարդիկ և այլն) և վերլուծում և կանխատեսում դրանց հատկությունները: Մենք նաև սովորում ենք ստատիկ միջավայրի մասին (օրինակ՝ ճանապարհի կառուցվածքը, արագության սահմանափակումները, լուսացույցները և այլն): Եթե մենք ավելի մանրամասն լինեինք, ապա կհայտնաբերեինք նաև համընդհանուր խոչընդոտներ։ Կարճ ասած, այս ընկալումների արդյունքում ստացված տեղեկատվությունը կազմում է մեքենա վարելու բարդ տեսարանների ցուցադրման մոդել:
Այնուամենայնիվ, որոշ շատ ակնհայտ տեսարանների համար ներկայիս բացահայտ աբստրակցիան չի կարող ամբողջությամբ նկարագրել այն գործոնները, որոնք ազդում են դեպքի վայրում վարելու վարքագծի վրա, կամ առաջադրանքները, որոնք մենք պետք է սահմանենք, չափազանց աննշան են, և դժվար է թվարկել բոլոր պահանջվող առաջադրանքները: Հետևաբար, ծայրից ծայր համակարգերը ապահովում են (հնարավոր է, անուղղակիորեն) համապարփակ ներկայացում այս տեղեկատվությամբ PnC-ների վրա ավտոմատ և անկորուստ գործելու հույսով: Իմ կարծիքով, բոլոր համակարգերը, որոնք կարող են բավարարել այս պահանջը, կարելի է անվանել ընդհանրացված վերջից մինչև վերջ:
Ինչ վերաբերում է այլ խնդիրներին, ինչպիսիք են դինամիկ փոխազդեցության սցենարների որոշ օպտիմալացումներ, ես կարծում եմ, որ գոնե ոչ միայն ծայրից ծայր կարող է լուծել այս խնդիրները, և վերջից մինչև վերջ կարող է լավագույն լուծումը չլինել: Ավանդական մեթոդները կարող են լուծել այս խնդիրները, և, իհարկե, երբ տվյալների քանակը բավականաչափ մեծ է, վերջից մինչև վերջ կարող է ավելի լավ լուծում տալ:
Որոշ թյուրիմացություններ ծայրից ծայր ինքնավար վարման վերաբերյալ
1. Կառավարման ազդանշանները և ճանապարհային կետերը պետք է ելքային լինեն, որպեսզի դրանք լինեն ծայրից ծայր:
Եթե համաձայն եք վերը քննարկված լայն ծայրից ծայր հայեցակարգի հետ, ապա այս խնդիրը հեշտ է հասկանալ: End-to-end-ը պետք է ընդգծի տեղեկատվության առանց կորուստների փոխանցումը, այլ ոչ թե առաջադրանքի ծավալի ուղղակիորեն դուրսբերումը: Նեղ ծայրից ծայր մոտեցումը շատ անհարկի դժվարություններ կառաջացնի և կպահանջի բազմաթիվ գաղտնի լուծումներ՝ անվտանգությունն ապահովելու համար:
2. The end-to-end համակարգը պետք է հիմնված լինի մեծ մոդելների կամ մաքուր տեսողության վրա:
Չկա անհրաժեշտ կապ ծայրից ծայր ինքնավար վարման, խոշոր մոդելի ինքնավար վարման և զուտ տեսողական ինքնավար վարման միջև, քանի որ դրանք լիովին անկախ հասկացություններ են. ծայրից ծայր համակարգը պարտադիր չէ, որ առաջնորդվի մեծ մոդելներով, ոչ էլ պարտադիր կերպով առաջնորդվի մաքուր տեսլականով: -ից
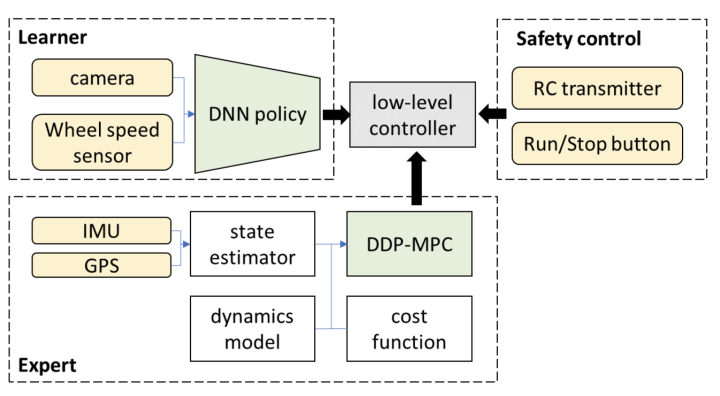
3. Երկարաժամկետ հեռանկարում հնարավո՞ր է, որ վերոհիշյալ ծայրից ծայր համակարգը նեղ իմաստով հասնի ինքնավար վարման L3 մակարդակից բարձր:
Այն, ինչ ներկայումս կոչվում է մաքուր «end-to-end» FSD-ի կատարումը հեռու է բավարար լինելուց L3 մակարդակում պահանջվող հուսալիությունն ու կայունությունը բավարարելու համար: Ավելի կոպիտ ասած, եթե ինքնակառավարման համակարգը ցանկանում է ընդունելի լինել հանրության կողմից, գլխավորն այն է, թե արդյոք հասարակությունը կարո՞ղ է ընդունել, որ որոշ դեպքերում մեքենան սխալներ կանի, և մարդիկ կարող են հեշտությամբ լուծել դրանք: Սա ավելի դժվար է մաքուր ծայրից ծայր համակարգի համար:
Օրինակ, Հյուսիսային Ամերիկայում և՛ Waymo-ն, և՛ Քրուզը բազմաթիվ վթարներ են ունեցել: Այնուամենայնիվ, Քրուզի վերջին վթարը հանգեցրեց երկու վիրավորի, թեև նման վթարները բավականին անխուսափելի են և ընդունելի մարդ վարորդների համար: Սակայն այս դժբախտ պատահարից հետո համակարգը սխալ գնահատեց վթարի վայրը և վիրավորի գտնվելու վայրը և իջեցրեց դիրքը դեպի «փուլ-օվեր» ռեժիմ, ինչի հետևանքով տուժածները երկար ժամանակ քաշվեցին: Այս պահվածքն անընդունելի է ցանկացած նորմալ մարդ վարորդի համար: Դա չի արվի, և արդյունքները շատ վատ կլինեն։
Ավելին, սա ահազանգ է, որով մենք պետք է ուշադիր քննարկենք, թե ինչպես խուսափել այս իրավիճակից ինքնավար վարորդական համակարգերի մշակման և շահագործման ժամանակ:
4. Այսպիսով, այս պահին, որո՞նք են գործնական լուծումները հաջորդ սերնդի զանգվածային արտադրության օժանդակ շարժիչ համակարգերի համար:
Իմ ներկայիս պատկերացումների համաձայն՝ վարման մեջ այսպես կոչված «end-to-end» մոդելն օգտագործելիս, հետագիծը դուրս բերելուց հետո այն կվերադարձնի ավանդական մեթոդների վրա հիմնված լուծում: Որպես այլընտրանք, ուսուցման վրա հիմնված պլանավորողները և հետագծի պլանավորման ավանդական ալգորիթմները միաժամանակ մի քանի հետագծեր են թողարկում, այնուհետև ընտրիչի միջոցով ընտրում են մեկ հետագիծ:
Այս տեսակի թաքնված լուծումը և ընտրությունը սահմանափակում են այս կասկադային համակարգի կատարողականի վերին սահմանը, եթե այս համակարգի ճարտարապետությունն ընդունվի: Եթե այս մեթոդը դեռ հիմնված է մաքուր հետադարձ ուսուցման վրա, ապա անկանխատեսելի ձախողումներ տեղի կունենան, և ապահով լինելու նպատակն ընդհանրապես չի իրականացվի:
Եթե մենք դիտարկում ենք վերաօպտիմալացում կամ ընտրություն՝ օգտագործելով այս ելքային հետագծի ավանդական պլանավորման մեթոդները, ապա դա համարժեք է ուսուցման վրա հիմնված մեթոդով արտադրված հետագծին. հետևաբար, ինչու՞ մենք ուղղակիորեն չենք օպտիմալացնում և որոնում այս հետագիծը:
Իհարկե, որոշ մարդիկ կասեին, որ նման օպտիմալացման կամ որոնման խնդիրը ոչ ուռուցիկ է, ունի մեծ վիճակի տարածություն և անհնար է իրական ժամանակում գործարկել մեքենայի ներսում: Ես խնդրում եմ բոլորին ուշադիր քննարկել այս հարցը. անցած տասը տարիների ընթացքում ընկալման համակարգը ստացել է առնվազն հարյուրապատիկ հաշվողական հզորության դիվիդենտ, իսկ մեր PnC մոդուլը:
Եթե մենք նաև թույլ տանք PnC մոդուլին օգտագործել մեծ հաշվողական հզորություն՝ զուգորդված վերջին տարիների օպտիմալացման առաջադեմ ալգորիթմների որոշ առաջընթացների հետ, արդյոք այս եզրակացությունը դեռ ճի՞շտ է: Այս տեսակի խնդրի համար մենք պետք է հաշվի առնենք, թե ինչն է ճիշտ առաջին սկզբունքներից:
5. Ինչպե՞ս հաշտեցնել տվյալների վրա հիմնված և ավանդական մեթոդների միջև կապը:
Շախմատ խաղալը օրինակ է, որը շատ նման է ինքնավար վարմանը: Այս տարվա փետրվարին Deepmind-ը հրապարակեց մի հոդված, որը կոչվում էր «Grandmaster-Level Chess Without Search»՝ քննարկելով, թե արդյոք հնարավոր է օգտագործել միայն տվյալների վրա հիմնված և հրաժարվել MCTS որոնումից AlphaGo-ում և AlphaZero-ում: Ինքնավար վարման նման, միայն մեկ ցանց է օգտագործվում ուղղակիորեն ելքային գործողությունների համար, մինչդեռ բոլոր հետագա քայլերն անտեսվում են:
Հոդվածը եզրակացնում է, որ, չնայած զգալի քանակությամբ տվյալների և մոդելի պարամետրերին, բավականին ողջամիտ արդյունքներ կարելի է ստանալ առանց որոնում օգտագործելու: Այնուամենայնիվ, կան զգալի տարբերություններ՝ համեմատած որոնում օգտագործող մեթոդների հետ: Սա հատկապես օգտակար է որոշ բարդ վերջնախաղերի հետ գործ ունենալու համար:
Բարդ սցենարների կամ անկյունային դեպքերի համար, որոնք պահանջում են բազմաքայլ խաղեր, այս անալոգիան դեռևս դժվարացնում է ավանդական օպտիմալացումից կամ որոնման ալգորիթմներից ամբողջությամբ հրաժարվելը: AlphaZero-ի նման տարբեր տեխնոլոգիաների առավելությունների ողջամտորեն օգտագործումը կատարողականությունը բարելավելու լավագույն միջոցն է:

6. Ավանդական մեթոդ = կանոնների վրա հիմնված, եթե այլ բան:
Ես ստիպված եմ եղել նորից ու նորից շտկել այս հայեցակարգը շատերի հետ զրուցելիս: Շատերը կարծում են, որ քանի դեռ այն զուտ տվյալների վրա հիմնված չէ, կանոնների վրա հիմնված չէ: Օրինակ՝ շախմատում բանաձևերի և շախմատի ռեկորդների անգիր անելը կանոնների վրա է հիմնված, բայց ինչպես AlphaGo-ն և AlphaZero-ն, այն մոդելին տալիս է ռացիոնալ լինելու հնարավորություն՝ օպտիմալացման և որոնման միջոցով: Չեմ կարծում, որ դա կարելի է անվանել կանոնների վրա հիմնված։
Այդ պատճառով մեծ մոդելն ինքնին ներկայումս բացակայում է, և հետազոտողները փորձում են ապահովել ուսուցման վրա հիմնված մոդել այնպիսի մեթոդների միջոցով, ինչպիսիք են CoT-ը: Այնուամենայնիվ, ի տարբերություն առաջադրանքների, որոնք պահանջում են զուտ տվյալների վրա հիմնված պատկերի ճանաչում և անբացատրելի պատճառներ, մեքենա վարող անձի յուրաքանչյուր գործողություն ունի հստակ շարժիչ ուժ:
Համապատասխան ալգորիթմի ճարտարապետության նախագծման համաձայն՝ որոշման հետագիծը պետք է դառնա փոփոխական և միատեսակ օպտիմիզացվի գիտական նպատակների առաջնորդության ներքո, այլ ոչ թե ստիպողաբար կարկատել և կարգավորել պարամետրերը՝ տարբեր դեպքեր շտկելու համար: Նման համակարգը, բնականաբար, չունի բոլոր տեսակի կոշտ կոդավորված տարօրինակ կանոններ։
Եզրակացություն
Մի խոսքով, վերջից մինչև վերջ կարող է լինել խոստումնալից տեխնիկական երթուղի, բայց թե ինչպես է հայեցակարգը կիրառվում, ավելի շատ հետազոտություն է պահանջում: Կարծում եմ՝ տվյալների և մոդելի պարամետրերի մի խումբ միակ ճիշտ լուծումը չէ, և եթե մենք ուզում ենք գերազանցել մյուսներին, պետք է շարունակենք քրտնաջան աշխատել:
Հրապարակման ժամանակը՝ ապրիլի 24-2024