
エンドツーエンドの自動運転システムをどう定義するか?
最も一般的な定義は、「エンドツーエンド」システムとは、生のセンサー情報を入力し、関係する変数をタスクに直接出力するシステムであるということです。たとえば、画像認識において、CNN は従来の特徴 + 分類子手法と比較して「エンドツーエンド」と言えます。
自動運転タスクでは、さまざまなセンサー (カメラ、LiDAR、レーダー、IMU など) からのデータが入力され、車両制御信号 (スロットルやハンドル角度など) が直接出力されます。さまざまな車両モデルの適応問題を考慮するために、出力を車両の走行軌跡に合わせて緩和することもできます。
この基盤に基づいて、最終出力制御信号またはウェイポイントに加えて、関連する中間タスクの監視を導入することによってパフォーマンスを向上させる、UniAD などのモジュール式のエンドツーエンド概念も登場しました。しかし、そのような狭い定義からすると、エンドツーエンドの本質は感覚情報のロスレス伝送であるはずです。
まず、非エンドツーエンド システムにおけるセンシング モジュールと PnC モジュールの間のインターフェイスを確認してみましょう。通常、ホワイトリストに登録されたオブジェクト (車、人など) を検出し、そのプロパティを分析して予測します。また、静的な環境(道路の構造、制限速度、信号など)についても学びます。もっと詳しく調べれば、普遍的な障害物も検出できるでしょう。つまり、これらの知覚によって出力される情報は、複雑な運転シーンの表示モデルを構成します。
ただし、一部の非常に明白なシーンでは、現在の明示的な抽象化ではシーン内の運転動作に影響を与える要因を完全に説明できなかったり、定義する必要があるタスクが些細すぎて、必要なタスクをすべて列挙することが困難です。したがって、エンドツーエンド システムは、この情報を使用して PnC に対して自動的かつロスレスで動作することを期待して、(おそらく暗黙的に) 包括的な表現を提供します。私の意見では、この要件を満たすことができるすべてのシステムは、汎用化されたエンドツーエンドと呼ぶことができます。
動的な対話シナリオの最適化などの他の問題に関しては、少なくともエンドツーエンドだけでこれらの問題を解決できるわけではなく、エンドツーエンドが最良の解決策ではない可能性もあると私は考えています。従来の方法でもこれらの問題を解決できますが、もちろん、データ量が十分に大きい場合には、エンドツーエンドの方がより良い解決策が提供される可能性があります。
エンドツーエンドの自動運転に関するいくつかの誤解
1. 制御信号とウェイポイントはエンドツーエンドで出力される必要があります。
上で説明した広範なエンドツーエンドの概念に同意する場合、この問題は簡単に理解できます。エンドツーエンドでは、タスク量を直接出力することよりも、情報のロスレス伝送を重視する必要があります。狭いエンドツーエンドのアプローチでは、多くの不必要なトラブルが発生し、安全性を確保するために多くの秘密の解決策が必要になります。
2.エンドツーエンドのシステムは、大規模なモデルまたは純粋なビジョンに基づいている必要があります。
エンドツーエンドの自動運転、大型モデルの自動運転、および純粋に視覚的な自動運転は完全に独立した概念であるため、これらの間に必然的な関連性はありません。エンドツーエンド システムは、必ずしも大規模なモデルによって駆動されるわけではなく、必ずしも純粋なビジョンによって駆動されるわけでもありません。の。
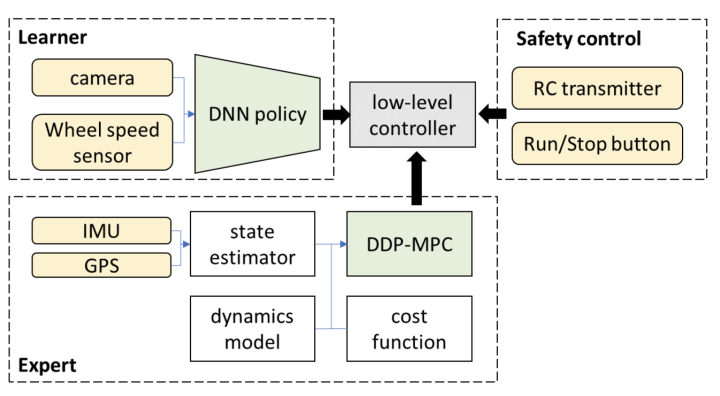
3.長期的には、上記の狭義のエンドツーエンドシステムでL3レベル以上の自動運転を実現することは可能でしょうか?
現在純粋なエンドツーエンド FSD と呼ばれるもののパフォーマンスは、L3 レベルで必要とされる信頼性と安定性を満たすには程遠いです。もっと率直に言うと、自動運転システムが国民に受け入れられたいのであれば、場合によっては機械がミスをするが、それを人間が簡単に解決できるということを国民が受け入れられるかどうかが鍵となる。これは、純粋なエンドツーエンド システムではさらに困難です。
たとえば、北米ではWaymoとCruiseの両方が多くの事故を起こしています。しかし、クルーズの最後の事故では2名が負傷したが、そのような事故は人間のドライバーにとってはかなり避けられず許容できるものである。しかし、この事故後、システムが事故位置と負傷者の位置を誤って停止させ、負傷者が長時間引きずられる事態が発生した。この動作は、通常の人間のドライバーには受け入れられません。それは実行されず、結果は非常に悪いものになるでしょう。
さらに、これは、自動運転システムの開発と運用において、この状況を回避する方法を慎重に検討する必要があるという警鐘でもあります。
4.では現時点で、次世代の量産型運転支援システムのための実用的な解決策は何でしょうか?
私の現在の理解では、いわゆるエンドツーエンドモデルを運転に使用する場合、軌跡を出力した後、従来の方法に基づいた解を返すことになります。あるいは、学習ベースのプランナーと従来の軌道計画アルゴリズムは複数の軌道を同時に出力し、セレクターを通じて 1 つの軌道を選択します。
このシステム アーキテクチャが採用されている場合、この種の秘密の解決策と選択により、このカスケード システムのパフォーマンスの上限が制限されます。この方法が依然として純粋なフィードバック学習に基づいている場合、予期しない障害が発生し、安全であるという目標はまったく達成されません。
この出力軌跡に対して従来の計画手法を使用して再最適化または選択することを考慮すると、これは学習駆動型手法によって生成された軌跡と同等になります。したがって、この軌道を直接最適化して検索してみませんか?
もちろん、そのような最適化や探索問題は非凸であり、状態空間が大きく、車載システムでリアルタイムに実行することは不可能であると言う人もいるでしょう。この質問については、皆さんに慎重に検討していただきたいと思います。過去 10 年間で、知覚システムは少なくとも 100 倍の計算能力を獲得しましたが、PnC モジュールはどうでしょうか?
近年の高度な最適化アルゴリズムの進歩と組み合わせて、PnC モジュールが大きな計算能力を使用できるようにしたとしても、この結論は依然として正しいでしょうか?この種の問題では、第一原理から何が正しいかを考えるべきです。
5.データ駆動型と従来の手法の関係をどのように調整するか?
チェスは自動運転とよく似た例です。今年 2 月、Deepmind は「検索なしのグランドマスター レベルのチェス」と呼ばれる記事を公開し、AlphaGo と AlphaZero でデータ駆動のみを使用し、MCTS 検索を放棄することが実現可能かどうかについて議論しました。自動運転と同様に、アクションを直接出力するために 1 つのネットワークのみが使用され、その後のステップはすべて無視されます。
この記事では、大量のデータとモデル パラメーターにもかかわらず、検索を使用しなくてもかなり妥当な結果が得られると結論付けています。ただし、検索を使用する方法と比較すると大きな違いがあります。これは、複雑なエンドゲームに対処する場合に特に役立ちます。
マルチステップ ゲームを必要とする複雑なシナリオやコーナー ケースの場合、このアナロジーにより、従来の最適化アルゴリズムや検索アルゴリズムを完全に放棄することが依然として困難になります。 AlphaZero のようなさまざまなテクノロジーの利点を合理的に利用することが、パフォーマンスを向上させる最善の方法です。

6.従来の方法 = ルールベースの場合は?
多くの人と話しながら、このコンセプトを何度も修正する必要がありました。多くの人は、純粋にデータ駆動型でない限り、ルールベースではないと信じています。たとえば、チェスでは、公式やチェスの記録を丸暗記することはルールに基づいていますが、AlphaGo や AlphaZero と同様に、最適化と検索を通じてモデルに合理的な能力を与えます。それはルールベースとは言えないと思います。
このため、現在は大規模なモデル自体が存在せず、研究者らはCoTなどの手法を通じて学習駆動型のモデルを提供しようとしている。ただし、純粋なデータに基づいた画像認識や説明できない理由が必要なタスクとは異なり、運転者のすべての行動には明確な原動力があります。
適切なアルゴリズム アーキテクチャ設計の下では、さまざまなケースを解決するためにパラメータを強制的にパッチして調整するのではなく、意思決定の軌道が可変となり、科学的目標に基づいて均一に最適化される必要があります。このようなシステムには、当然のことながら、あらゆる種類のハードコーディングされた奇妙なルールが存在するわけではありません。
結論
つまり、エンドツーエンドは有望な技術的ルートである可能性がありますが、この概念をどのように適用するかについてはさらなる研究が必要です。大量のデータやモデルパラメータだけが唯一の正解ではないと思います。他を超えたいのであれば、努力し続ける必要があります。
投稿日時: 2024 年 4 月 24 日