
ວິທີການກໍານົດລະບົບການຂັບຂີ່ອັດຕະໂນມັດແບບ end-to-end?
ຄໍານິຍາມທົ່ວໄປທີ່ສຸດແມ່ນວ່າລະບົບ "end-to-end" ແມ່ນລະບົບທີ່ປ້ອນຂໍ້ມູນເຊັນເຊີດິບແລະສົ່ງຜົນໄດ້ຮັບໂດຍກົງຂອງຕົວແປທີ່ກ່ຽວຂ້ອງກັບວຽກງານ. ຕົວຢ່າງ, ໃນການຮັບຮູ້ຮູບພາບ, CNN ສາມາດເອີ້ນວ່າ "ສິ້ນສຸດ" ເມື່ອທຽບກັບລັກສະນະພື້ນເມືອງ + ວິທີການຈັດປະເພດ.
ໃນວຽກງານການຂັບຂີ່ແບບອັດຕະໂນມັດ, ຂໍ້ມູນຈາກເຊັນເຊີຕ່າງໆ (ເຊັ່ນ: ກ້ອງຖ່າຍຮູບ, LiDAR, Radar, ຫຼື IMU...) ແມ່ນ input, ແລະສັນຍານການຄວບຄຸມຍານພາຫະນະ (ເຊັ່ນ: throttle ຫຼືມຸມພວງມາໄລ) ແມ່ນຜົນຜະລິດໂດຍກົງ. ເພື່ອພິຈາລະນາບັນຫາການປັບຕົວຂອງຮູບແບບຍານພາຫະນະທີ່ແຕກຕ່າງກັນ, ຜົນຜະລິດຍັງສາມາດຜ່ອນຄາຍກັບເສັ້ນທາງການຂັບຂີ່ຂອງຍານພາຫະນະ.
ອີງໃສ່ພື້ນຖານນີ້, ແນວຄວາມຄິດຂອງ end-to-end modular ຍັງເກີດຂື້ນ, ເຊັ່ນ UniAD, ເຊິ່ງປັບປຸງການປະຕິບັດໂດຍການແນະນໍາການຊີ້ນໍາຂອງວຽກງານລະດັບກາງທີ່ກ່ຽວຂ້ອງ, ນອກເຫນືອຈາກສັນຍານການຄວບຄຸມຜົນໄດ້ຮັບສຸດທ້າຍຫຼືຈຸດທາງ. ຢ່າງໃດກໍຕາມ, ຈາກຄໍານິຍາມແຄບດັ່ງກ່າວ, ໂດຍເນື້ອແທ້ແລ້ວຂອງ end-to-end ຄວນຈະເປັນການສົ່ງຜ່ານການສູນເສຍຂອງຂໍ້ມູນຂ່າວສານ sensory.
ໃຫ້ພວກເຮົາທົບທວນຄືນການໂຕ້ຕອບລະຫວ່າງ sensing ແລະ PnC modules ໃນລະບົບທີ່ບໍ່ແມ່ນ end-to-end. ໂດຍປົກກະຕິແລ້ວ, ພວກເຮົາກວດພົບວັດຖຸທີ່ຖືກບັນຊີຂາວ (ເຊັ່ນ: ລົດ, ຄົນ, ແລະອື່ນໆ) ແລະວິເຄາະ ແລະຄາດຄະເນຄຸນສົມບັດຂອງພວກມັນ. ພວກເຮົາຍັງໄດ້ຮຽນຮູ້ກ່ຽວກັບສະພາບແວດລ້ອມຄົງທີ່ (ເຊັ່ນ: ໂຄງສ້າງຖະໜົນ, ການຈຳກັດຄວາມໄວ, ໄຟຈະລາຈອນ, ແລະອື່ນໆ). ຖ້າຫາກວ່າພວກເຮົາໄດ້ລະອຽດຫຼາຍ, ພວກເຮົາຍັງຈະກວດພົບອຸປະສັກທົ່ວໄປ. ໃນສັ້ນ, ຜົນຜະລິດຂໍ້ມູນຂ່າວສານໂດຍການຮັບຮູ້ເຫຼົ່ານີ້ປະກອບເປັນຮູບແບບການສະແດງຂອງ scenes ການຂັບລົດສະລັບສັບຊ້ອນ.
ຢ່າງໃດກໍ່ຕາມ, ສໍາລັບບາງສາກທີ່ຊັດເຈນຫຼາຍ, ຄວາມບໍ່ຊັດເຈນໃນປັດຈຸບັນບໍ່ສາມາດອະທິບາຍໄດ້ຢ່າງເຕັມສ່ວນກ່ຽວກັບປັດໃຈທີ່ມີຜົນກະທົບຕໍ່ພຶດຕິກໍາການຂັບຂີ່ໃນ scene, ຫຼືວຽກງານທີ່ພວກເຮົາຕ້ອງການກໍານົດແມ່ນເລັກນ້ອຍເກີນໄປ, ແລະມັນກໍ່ເປັນການຍາກທີ່ຈະນັບທຸກຫນ້າວຽກທີ່ຕ້ອງການ. ດັ່ງນັ້ນ, ລະບົບ end-to-end ສະຫນອງການເປັນຕົວແທນທີ່ສົມບູນແບບ (ບາງທີ implicitly) ດ້ວຍຄວາມຫວັງທີ່ຈະປະຕິບັດອັດຕະໂນມັດແລະການສູນເສຍຕໍ່ PnCs ກັບຂໍ້ມູນນີ້. ໃນຄວາມຄິດເຫັນຂອງຂ້າພະເຈົ້າ, ລະບົບທັງຫມົດທີ່ສາມາດຕອບສະຫນອງຄວາມຕ້ອງການນີ້ສາມາດເອີ້ນວ່າທົ່ວໄປ end-to-end.
ສໍາລັບບັນຫາອື່ນໆ, ເຊັ່ນການເພີ່ມປະສິດທິພາບບາງຢ່າງຂອງສະຖານະການການໂຕ້ຕອບແບບເຄື່ອນໄຫວ, ຂ້າພະເຈົ້າເຊື່ອວ່າຢ່າງຫນ້ອຍບໍ່ພຽງແຕ່ end-to-end ສາມາດແກ້ໄຂບັນຫາເຫຼົ່ານີ້, ແລະ end-to-end ອາດຈະບໍ່ເປັນການແກ້ໄຂທີ່ດີທີ່ສຸດ. ວິທີການແບບດັ້ງເດີມສາມາດແກ້ໄຂບັນຫາເຫຼົ່ານີ້ໄດ້, ແລະແນ່ນອນ, ເມື່ອຈໍານວນຂໍ້ມູນມີຂະຫນາດໃຫຍ່ພຽງພໍ, ໃນຕອນທ້າຍອາດຈະສະຫນອງການແກ້ໄຂທີ່ດີກວ່າ.
ຄວາມເຂົ້າໃຈຜິດບາງຢ່າງກ່ຽວກັບການຂັບຂີ່ແບບອັດຕະໂນມັດໃນຕອນທ້າຍ
1. ສັນຍານຄວບຄຸມ ແລະຈຸດທາງຕ້ອງເປັນຜົນອອກເພື່ອໃຫ້ເປັນຈຸດຈົບ.
ຖ້າທ່ານຕົກລົງເຫັນດີກັບແນວຄວາມຄິດທີ່ກວ້າງຂວາງທີ່ສຸດທີ່ໄດ້ກ່າວມາຂ້າງເທິງ, ບັນຫານີ້ແມ່ນເຂົ້າໃຈງ່າຍ. End-to-end ຄວນເນັ້ນຫນັກເຖິງການສົ່ງຂໍ້ມູນທີ່ບໍ່ມີການສູນເສຍແທນທີ່ຈະເຮັດໃຫ້ປະລິມານວຽກງານໂດຍກົງ. ວິທີການທ້າຍແຄບຈະເຮັດໃຫ້ເກີດບັນຫາທີ່ບໍ່ຈໍາເປັນຫຼາຍແລະຮຽກຮ້ອງໃຫ້ມີການແກ້ໄຂຄວາມລັບຫຼາຍເພື່ອຮັບປະກັນຄວາມປອດໄພ.
2.The end-to-end ລະບົບຕ້ອງອີງໃສ່ແບບຈໍາລອງຂະຫນາດໃຫຍ່ຫຼືວິໄສທັດທີ່ບໍລິສຸດ.
ບໍ່ມີການເຊື່ອມຕໍ່ທີ່ຈໍາເປັນລະຫວ່າງການຂັບລົດອັດຕະໂນມັດແບບ end-to-end, ການຂັບລົດອັດຕະໂນມັດແບບຈໍາລອງຂະຫນາດໃຫຍ່, ແລະການຂັບຂີ່ແບບອັດຕະໂນມັດທີ່ມີສາຍຕາອັນບໍລິສຸດເພາະວ່າພວກເຂົາເປັນແນວຄວາມຄິດທີ່ເປັນເອກະລາດຢ່າງສົມບູນ; ລະບົບ end-to-end ບໍ່ຈໍາເປັນຕ້ອງຂັບເຄື່ອນໂດຍແບບຈໍາລອງຂະຫນາດໃຫຍ່, ແລະບໍ່ຈໍາເປັນຕ້ອງຂັບເຄື່ອນໂດຍວິໄສທັດອັນບໍລິສຸດ. ຂອງ.
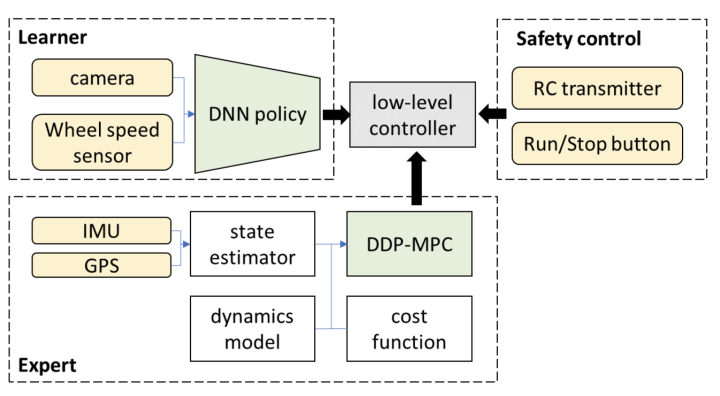
3. ໃນໄລຍະຍາວ, ມັນເປັນໄປໄດ້ສໍາລັບລະບົບ end-to-end ທີ່ໄດ້ກ່າວມາຂ້າງເທິງໃນຄວາມຮູ້ສຶກແຄບທີ່ຈະບັນລຸການຂັບລົດອັດຕະໂນມັດຂ້າງເທິງລະດັບ L3?
ການປະຕິບັດຂອງສິ່ງທີ່ເອີ້ນວ່າ FSD ໃນຕອນທ້າຍອັນບໍລິສຸດໃນປັດຈຸບັນແມ່ນຢູ່ໄກຈາກພຽງພໍເພື່ອຕອບສະຫນອງຄວາມຫນ້າເຊື່ອຖືແລະຄວາມຫມັ້ນຄົງທີ່ຕ້ອງການໃນລະດັບ L3. ເວົ້າຢ່າງເຄັ່ງຄັດກວ່າ, ຖ້າລະບົບຂັບລົດດ້ວຍຕົນເອງຕ້ອງການໄດ້ຮັບການຍອມຮັບຈາກປະຊາຊົນ, ທີ່ສໍາຄັນແມ່ນວ່າປະຊາຊົນສາມາດຍອມຮັບໄດ້ວ່າໃນບາງກໍລະນີ, ເຄື່ອງຈັກຈະເຮັດຜິດພາດ, ແລະມະນຸດສາມາດແກ້ໄຂໄດ້ງ່າຍ. ນີ້ແມ່ນຍາກກວ່າສໍາລັບລະບົບ end-to-end ທີ່ບໍລິສຸດ.
ຕົວຢ່າງເຊັ່ນ, ທັງ Waymo ແລະ Cruise ໃນອາເມລິກາເຫນືອມີອຸປະຕິເຫດຫຼາຍ. ຢ່າງໃດກໍ່ຕາມ, ອຸປະຕິເຫດຄັ້ງສຸດທ້າຍຂອງ Cruise ເຮັດໃຫ້ມີຜູ້ບາດເຈັບ 2 ຄົນ, ເຖິງແມ່ນວ່າອຸປະຕິເຫດດັ່ງກ່າວເປັນສິ່ງທີ່ບໍ່ສາມາດຫຼີກລ່ຽງໄດ້ແລະເປັນທີ່ຍອມຮັບສໍາລັບຜູ້ຂັບຂີ່ຂອງມະນຸດ. ແນວໃດກໍ່ຕາມ, ຫຼັງຈາກອຸປະຕິເຫດນີ້, ລະບົບການ misjudge ສະຖານທີ່ຂອງອຸປະຕິເຫດແລະສະຖານທີ່ຂອງຜູ້ບາດເຈັບແລະ downgraded ເປັນຮູບແບບດຶງ, ເຮັດໃຫ້ຜູ້ບາດເຈັບຖືກລາກເປັນເວລາດົນນານ. ພຶດຕິກຳນີ້ບໍ່ສາມາດຍອມຮັບໄດ້ຕໍ່ກັບຄົນຂັບທຳມະດາຄົນໃດຄົນໜຶ່ງ. ມັນຈະບໍ່ເຮັດ, ແລະຜົນໄດ້ຮັບຈະບໍ່ດີຫຼາຍ.
ຍິ່ງໄປກວ່ານັ້ນ, ນີ້ແມ່ນການປຸກທີ່ພວກເຮົາຈະພິຈາລະນາຢ່າງລະມັດລະວັງວິທີການຫຼີກເວັ້ນສະຖານະການນີ້ໃນລະຫວ່າງການພັດທະນາແລະການດໍາເນີນງານຂອງລະບົບການຂັບຂີ່ອັດຕະໂນມັດ.
4. ດັ່ງນັ້ນ, ໃນເວລານີ້, ວິທີແກ້ໄຂທີ່ປະຕິບັດໄດ້ສໍາລັບການຜະລິດລະບົບການຊ່ວຍຂັບລົດທີ່ຜະລິດໂດຍມະຫາຊົນ?
ອີງຕາມຄວາມເຂົ້າໃຈໃນປະຈຸບັນຂອງຂ້ອຍ, ເມື່ອນໍາໃຊ້ຮູບແບບທີ່ເອີ້ນວ່າ end-to-end ໃນການຂັບລົດ, ຫຼັງຈາກຜົນໄດ້ຮັບຂອງ trajectory, ມັນຈະກັບຄືນການແກ້ໄຂໂດຍອີງໃສ່ວິທີການພື້ນເມືອງ. ອີກທາງເລືອກ, ນັກວາງແຜນທີ່ອີງໃສ່ການຮຽນຮູ້ແລະສູດການວາງແຜນເສັ້ນທາງແບບດັ້ງເດີມຈະໃຫ້ຜົນໄດ້ຮັບຫຼາຍເສັ້ນທາງພ້ອມໆກັນແລະຫຼັງຈາກນັ້ນເລືອກເອົາຫນຶ່ງ trajectory ຜ່ານຕົວເລືອກ.
ປະເພດຂອງການແກ້ໄຂຄວາມລັບແລະທາງເລືອກນີ້ຈໍາກັດຂອບເຂດຈໍາກັດດ້ານເທິງຂອງການປະຕິບັດຂອງລະບົບ cascade ຖ້າສະຖາປັດຕະຍະກໍາລະບົບນີ້ຖືກຮັບຮອງເອົາ. ຖ້າວິທີການນີ້ຍັງອີງໃສ່ການຮຽນຮູ້ຄໍາຄຶດຄໍາເຫັນທີ່ບໍລິສຸດ, ຄວາມລົ້ມເຫຼວທີ່ບໍ່ສາມາດຄາດເດົາໄດ້ຈະເກີດຂື້ນແລະເປົ້າຫມາຍຂອງຄວາມປອດໄພຈະບໍ່ປະສົບຜົນສໍາເລັດທັງຫມົດ.
ຖ້າພວກເຮົາພິຈາລະນາການເພີ່ມປະສິດທິພາບຄືນໃຫມ່ຫຼືເລືອກການນໍາໃຊ້ວິທີການວາງແຜນແບບດັ້ງເດີມກ່ຽວກັບເສັ້ນທາງຜົນຜະລິດນີ້, ນີ້ເທົ່າກັບ trajectory ທີ່ຜະລິດໂດຍວິທີການຮຽນຮູ້; ດັ່ງນັ້ນ, ເປັນຫຍັງພວກເຮົາຈຶ່ງບໍ່ເພີ່ມປະສິດທິພາບໂດຍກົງ ແລະຄົ້ນຫາເສັ້ນທາງນີ້?
ແນ່ນອນ, ບາງຄົນຈະເວົ້າວ່າການເພີ່ມປະສິດທິພາບດັ່ງກ່າວຫຼືບັນຫາການຄົ້ນຫາແມ່ນບໍ່ໂຄ້ງ, ມີພື້ນທີ່ຂອງລັດຂະຫນາດໃຫຍ່, ແລະເປັນໄປບໍ່ໄດ້ທີ່ຈະດໍາເນີນການໃນເວລາທີ່ແທ້ຈິງໃນລະບົບໃນຍານພາຫະນະ. ຂ້າພະເຈົ້າຮຽກຮ້ອງໃຫ້ທຸກຄົນພິຈາລະນາຄໍາຖາມນີ້ຢ່າງລະມັດລະວັງ: ໃນສິບປີທີ່ຜ່ານມາ, ລະບົບການຮັບຮູ້ໄດ້ຮັບເງິນປັນຜົນຂອງຄອມພິວເຕີ້ຢ່າງຫນ້ອຍຫນຶ່ງຮ້ອຍເທົ່າ, ແຕ່ວ່າໂມດູນ PnC ຂອງພວກເຮົາແມ່ນຫຍັງ?
ຖ້າພວກເຮົາຍັງອະນຸຍາດໃຫ້ໂມດູນ PnC ໃຊ້ພະລັງງານຄອມພິວເຕີ້ຂະຫນາດໃຫຍ່, ສົມທົບກັບຄວາມກ້າວຫນ້າບາງຢ່າງໃນລະບົບການເພີ່ມປະສິດທິພາບຂັ້ນສູງໃນຊຸມປີທີ່ຜ່ານມາ, ການສະຫລຸບນີ້ຍັງຖືກຕ້ອງບໍ? ສໍາລັບບັນຫາປະເພດນີ້, ພວກເຮົາຄວນພິຈາລະນາສິ່ງທີ່ຖືກຕ້ອງຈາກຫຼັກການທໍາອິດ.
5.How to reconcile ຄວາມສໍາພັນລະຫວ່າງຂໍ້ມູນທີ່ຂັບເຄື່ອນແລະວິທີການພື້ນເມືອງ?
ການຫຼິ້ນໝາກຮຸກເປັນຕົວຢ່າງທີ່ຄ້າຍຄືກັນກັບການຂັບຂີ່ແບບອັດຕະໂນມັດ. ໃນເດືອນກຸມພາຂອງປີນີ້, Deepmind ຈັດພີມມາບົດຄວາມທີ່ເອີ້ນວ່າ "Grandmaster-Level Chess ໂດຍບໍ່ມີການຄົ້ນຫາ", ປຶກສາຫາລືວ່າມັນເປັນໄປໄດ້ພຽງແຕ່ນໍາໃຊ້ຂໍ້ມູນແລະປະຖິ້ມການຄົ້ນຫາ MCTS ໃນ AlphaGo ແລະ AlphaZero. ຄ້າຍຄືກັນກັບການຂັບຂີ່ແບບອັດຕະໂນມັດ, ມີພຽງເຄືອຂ່າຍດຽວທີ່ໃຊ້ເພື່ອສົ່ງຜົນອອກມາໂດຍກົງ, ໃນຂະນະທີ່ທຸກຂັ້ນຕອນຕໍ່ໄປຈະຖືກລະເລີຍ.
ບົດຄວາມສະຫຼຸບວ່າ, ເຖິງວ່າຈະມີຂໍ້ມູນຈໍານວນຫຼວງຫຼາຍແລະຕົວກໍານົດການແບບຈໍາລອງ, ຜົນໄດ້ຮັບທີ່ສົມເຫດສົມຜົນສາມາດໄດ້ຮັບໂດຍບໍ່ຕ້ອງໃຊ້ການຄົ້ນຫາ. ຢ່າງໃດກໍ່ຕາມ, ມີຄວາມແຕກຕ່າງກັນຢ່າງຫຼວງຫຼາຍເມື່ອທຽບກັບວິທີການທີ່ໃຊ້ການຄົ້ນຫາ. ນີ້ແມ່ນເປັນປະໂຫຍດໂດຍສະເພາະສໍາລັບການຈັດການກັບບາງ endgames ສະລັບສັບຊ້ອນ.
ສໍາລັບສະຖານະການທີ່ສັບສົນຫຼືກໍລະນີແຈທີ່ຕ້ອງການເກມຫຼາຍຂັ້ນຕອນ, ການປຽບທຽບນີ້ຍັງເຮັດໃຫ້ມັນຍາກທີ່ຈະປະຖິ້ມການເພີ່ມປະສິດທິພາບແບບດັ້ງເດີມຫຼືວິທີການຄົ້ນຫາຢ່າງສິ້ນເຊີງ. ການນໍາໃຊ້ຄວາມໄດ້ປຽບຂອງເຕັກໂນໂລຢີຕ່າງໆຢ່າງສົມເຫດສົມຜົນເຊັ່ນ AlphaZero ແມ່ນວິທີທີ່ດີທີ່ສຸດເພື່ອປັບປຸງການປະຕິບັດ.

6.Traditional method = rule-based if else?
ຂ້ອຍຕ້ອງແກ້ໄຂແນວຄວາມຄິດນີ້ເທື່ອແລ້ວເທື່ອໃນຂະນະທີ່ເວົ້າກັບຄົນຈໍານວນຫຼາຍ. ຫຼາຍຄົນເຊື່ອວ່າຕາບໃດທີ່ມັນບໍ່ໄດ້ຖືກຂັບເຄື່ອນໂດຍຂໍ້ມູນຢ່າງດຽວ, ມັນບໍ່ແມ່ນກົດລະບຽບ. ສໍາລັບຕົວຢ່າງ, ໃນຫມາກຮຸກ, ການຈື່ຈໍາສູດແລະບັນທຶກຫມາກຮຸກໂດຍ rote ແມ່ນກົດລະບຽບ, ແຕ່ຄືກັບ AlphaGo ແລະ AlphaZero, ມັນເຮັດໃຫ້ຕົວແບບມີຄວາມສາມາດສົມເຫດສົມຜົນໂດຍຜ່ານການເພີ່ມປະສິດທິພາບແລະການຄົ້ນຫາ. ຂ້ອຍບໍ່ຄິດວ່າມັນສາມາດເອີ້ນວ່າກົດລະບຽບ.
ເນື່ອງຈາກວ່ານີ້, ຮູບແບບຂະຫນາດໃຫຍ່ຕົວມັນເອງຍັງຂາດຫາຍໄປໃນປັດຈຸບັນ, ແລະນັກຄົ້ນຄວ້າກໍາລັງພະຍາຍາມສະຫນອງຕົວແບບການຮຽນຮູ້ໂດຍຜ່ານວິທີການເຊັ່ນ CoT. ແນວໃດກໍ່ຕາມ, ບໍ່ເຫມືອນກັບວຽກງານທີ່ຕ້ອງການການຮັບຮູ້ຮູບພາບທີ່ມີຂໍ້ມູນບໍລິສຸດແລະເຫດຜົນທີ່ບໍ່ສາມາດອະທິບາຍໄດ້, ທຸກໆການກະທໍາຂອງຄົນຂັບລົດມີຜົນບັງຄັບໃຊ້ທີ່ຊັດເຈນ.
ພາຍໃຕ້ການອອກແບບສະຖາປັດຕະຍະກໍາທີ່ເຫມາະສົມ, ເສັ້ນທາງການຕັດສິນໃຈຄວນຈະເປັນຕົວແປແລະຖືກປັບປຸງໃຫ້ເຫມາະສົມພາຍໃຕ້ການຊີ້ນໍາຂອງເປົ້າຫມາຍວິທະຍາສາດ, ແທນທີ່ຈະບັງຄັບໃຫ້ແກ້ໄຂແລະປັບຕົວກໍານົດການເພື່ອແກ້ໄຂກໍລະນີຕ່າງໆ. ລະບົບດັ່ງກ່າວຕາມທໍາມະຊາດບໍ່ມີທຸກປະເພດຂອງກົດລະບຽບແປກປະຫລາດທີ່ຍາກ.
ສະຫຼຸບ
ໃນສັ້ນ, end-to-end ອາດຈະເປັນເສັ້ນທາງດ້ານວິຊາການທີ່ໂດດເດັ່ນ, ແຕ່ວິທີການນໍາໃຊ້ແນວຄວາມຄິດແມ່ນຕ້ອງການການຄົ້ນຄວ້າເພີ່ມເຕີມ. ຂ້າພະເຈົ້າຄິດວ່າບັນດາຕົວກໍານົດການຂໍ້ມູນແລະຕົວແບບບໍ່ແມ່ນການແກ້ໄຂທີ່ຖືກຕ້ອງເທົ່ານັ້ນ, ແລະຖ້າພວກເຮົາຕ້ອງການທີ່ຈະລື່ນກາຍຄົນອື່ນ, ພວກເຮົາຕ້ອງເຮັດວຽກຫນັກ.
ເວລາປະກາດ: 24-04-2024