
အဆုံးမှ အဆုံးအထိ အလိုအလျောက် မောင်းနှင်မှုစနစ်အား မည်သို့သတ်မှတ်မည်နည်း။
အသုံးအများဆုံး အဓိပ္ပါယ်ဖွင့်ဆိုချက်မှာ "အဆုံးမှအဆုံး" စနစ်သည် ကုန်ကြမ်းအာရုံခံကိရိယာအချက်အလက်များကို ထည့်သွင်းပြီး အလုပ်နှင့်သက်ဆိုင်သည့် ကိန်းရှင်များကို တိုက်ရိုက်ထုတ်ပေးသည့် စနစ်ဖြစ်သည်။ ဥပမာအားဖြင့်၊ ရုပ်ပုံအသိအမှတ်ပြုခြင်းတွင်၊ CNN ကို ရိုးရာအင်္ဂါရပ် + အမျိုးအစားခွဲနည်းနည်းလမ်းနှင့် နှိုင်းယှဉ်ကာ "အဆုံးမှအဆုံး" ဟုခေါ်ဆိုနိုင်သည်။
အလိုအလျောက်မောင်းနှင်ခြင်းလုပ်ငန်းများတွင်၊ အာရုံခံကိရိယာအမျိုးမျိုးမှဒေတာများ (ကင်မရာများ၊ LiDAR၊ Radar သို့မဟုတ် IMU...) တို့ကို ထည့်သွင်းကြပြီး ယာဉ်ထိန်းချုပ်မှုအချက်ပြမှုများ (အခိုးအငွေ့ သို့မဟုတ် စတီယာရင်ဘီးထောင့်ကဲ့သို့သော) များကို တိုက်ရိုက်ထုတ်ပေးပါသည်။ မတူညီသော ယာဉ်မော်ဒယ်များ၏ လိုက်လျောညီထွေမှုဆိုင်ရာ ပြဿနာများကို ထည့်သွင်းစဉ်းစားရန်၊ အထွက်အားကိုလည်း ယာဉ်၏ မောင်းနှင်မှုလမ်းကြောင်းအတိုင်း ဖြေလျှော့ပေးနိုင်သည်။
ဤအခြေခံအုတ်မြစ်ကို အခြေခံ၍ နောက်ဆုံးထွက်ကုန်ထိန်းချုပ်မှုအချက်ပြမှုများ သို့မဟုတ် နည်းလမ်းအမှတ်များအပြင် သက်ဆိုင်ရာ အလယ်အလတ်အလုပ်များကို ကြီးကြပ်ခြင်းအား မိတ်ဆက်ခြင်းဖြင့် စွမ်းဆောင်ရည်ကို မြှင့်တင်ပေးသည့် UniAD ကဲ့သို့သော မော်ဂျူလာအဆုံးမှ အဆုံး အယူအဆများလည်း ပေါ်ထွက်လာပါသည်။ သို့ရာတွင် ဤကဲ့သို့ ကျဉ်းမြောင်းသော အဓိပ္ပါယ်ဖွင့်ဆိုချက်မှ အဆုံးမှ အဆုံး၏ အနှစ်သာရသည် အာရုံခံအချက်အလက်များ၏ ဆုံးရှုံးမှုမရှိသော ပေးပို့ခြင်းဖြစ်သင့်သည်။
အဆုံးမှအဆုံးမဟုတ်သောစနစ်များရှိ အာရုံခံစနစ်နှင့် PnC မော်ဂျူးများကြားရှိ အင်တာဖေ့စ်များကို ဦးစွာသုံးသပ်ကြည့်ကြပါစို့။ အများအားဖြင့်၊ ကျွန်ုပ်တို့သည် တရားဝင်စာရင်းသွင်းထားသော အရာဝတ္ထုများ (ကားများ၊ လူများစသည်) ကို ရှာဖွေပြီး ၎င်းတို့၏ ဂုဏ်သတ္တိများကို ခွဲခြမ်းစိတ်ဖြာပြီး ခန့်မှန်းကြသည်။ ကျွန်ုပ်တို့သည် တည်ငြိမ်သောပတ်ဝန်းကျင် (ဥပမာ လမ်းဖွဲ့စည်းပုံ၊ အမြန်နှုန်းကန့်သတ်ချက်များ၊ မီးပွိုင့်စသည်) အကြောင်းကိုလည်း လေ့လာပါသည်။ ကျွန်ုပ်တို့ ပို၍အသေးစိတ်ပြောပါက၊ ကျွန်ုပ်တို့သည် စကြာဝဠာအတားအဆီးများကို ရှာဖွေတွေ့ရှိနိုင်မည်ဖြစ်သည်။ အတိုချုပ်အားဖြင့်၊ အဆိုပါ ခံယူချက်များမှ အချက်အလက်များ ထွက်ပေါ်လာခြင်းသည် ရှုပ်ထွေးသော မောင်းနှင်မှုမြင်ကွင်းများ၏ ပြကွက်ပုံစံတစ်ခုဖြစ်သည်။
သို့သော် အချို့သော အလွန်သိသာထင်ရှားသော မြင်ကွင်းများအတွက်၊ လက်ရှိ ရှင်းလင်းပြတ်သားသော စိတ်ကူးယဉ်မှုသည် အခင်းဖြစ်ပွားရာနေရာရှိ ကားမောင်းနှင်မှုအမူအကျင့်ကို ထိခိုက်စေသည့် အကြောင်းရင်းများကို အပြည့်အ၀ မဖော်ပြနိုင်ဘဲ သို့မဟုတ် ကျွန်ုပ်တို့သတ်မှတ်ရန် လိုအပ်သော အလုပ်များသည် အသေးအဖွဲဖြစ်ပြီး လိုအပ်သည့်အလုပ်အားလုံးကို စာရင်းကောက်ယူရန် ခက်ခဲသည်။ ထို့ကြောင့်၊ အဆုံးမှအဆုံးစနစ်များသည် ဤအချက်အလက်များဖြင့် PnCs တွင် အလိုအလျောက်လုပ်ဆောင်ပြီး အရှုံးမရှိလုပ်ဆောင်မှုမျှော်လင့်ချက်ဖြင့် ကျယ်ကျယ်ပြန့်ပြန့် (ထင်မြင်ယူဆနိုင်သည်) ပြည့်စုံသောကိုယ်စားပြုမှုကို ပေးပါသည်။ ကျွန်တော့်အမြင်အရတော့ ဒီလိုအပ်ချက်ကို ဖြည့်ဆည်းပေးနိုင်တဲ့ စနစ်အားလုံးကို ယေဘုယျအားဖြင့် အဆုံးကနေ အဆုံးအထိ ခေါ်ဆိုနိုင်ပါတယ်။
တက်ကြွသောအပြန်အလှန်တုံ့ပြန်မှုအခြေအနေအချို့ကို ပိုမိုကောင်းမွန်အောင်ပြုလုပ်ခြင်းကဲ့သို့သော အခြားပြဿနာများအတွက်၊ အနည်းဆုံး အဆုံးမှအဆုံးအထိသာ ဤပြဿနာများကို ဖြေရှင်းပေးနိုင်သည်သာမက အဆုံးမှအဆုံးအထိ အကောင်းဆုံးဖြေရှင်းချက်မဟုတ်နိုင်ဟု ကျွန်ုပ်ယုံကြည်ပါသည်။ သမားရိုးကျနည်းလမ်းများသည် အဆိုပါပြဿနာများကို ဖြေရှင်းပေးနိုင်ပြီး ဒေတာပမာဏ အလုံအလောက်ကြီးနေသောအခါတွင်၊ အဆုံးမှ အဆုံးအထိ ပိုမိုကောင်းမွန်သော အဖြေကို ပေးစွမ်းနိုင်ပါသည်။
အဆုံးမှအဆုံး အလိုအလျောက်မောင်းနှင်ခြင်းနှင့်ပတ်သက်၍ နားလည်မှုလွဲမှားခြင်း။
1. ထိန်းချုပ်အချက်ပြမှုများနှင့် လမ်းပွိုင့်များသည် အဆုံးမှအဆုံးအထိ ထွက်ရပါမည်။
အထက်တွင်ဖော်ပြထားသော ကျယ်ပြန့်သောအဆုံးမှအဆုံးအယူအဆကို သင်သဘောတူပါက ဤပြဿနာကို နားလည်ရန်လွယ်ကူပါသည်။ လုပ်ငန်းပမာဏကို တိုက်ရိုက်ထုတ်ခြင်းထက် အဆုံးမှအဆုံးသို့ အချက်အလက်များ ဆုံးရှုံးမှုမရှိသော ထုတ်လွှင့်မှုကို အလေးပေးသင့်သည်။ ကျဉ်းမြောင်းသော အဆုံးမှအဆုံး ချဉ်းကပ်နည်းသည် မလိုအပ်သော ပြဿနာများစွာကို ဖြစ်စေပြီး ဘေးကင်းစေရန်အတွက် လျှို့ဝှက်ဖြေရှင်းချက်များစွာ လိုအပ်ပါသည်။
2. End-to-end စနစ်သည် ကြီးမားသော မော်ဒယ်များ သို့မဟုတ် သန့်စင်သော အမြင်ပေါ်တွင် အခြေခံရပါမည်။
၎င်းတို့သည် လုံးဝလွတ်လပ်သော သဘောတရားများဖြစ်သောကြောင့် အဆုံးမှအဆုံးသို့ အလိုအလျောက်မောင်းနှင်မှု၊ မော်ဒယ်ကြီးသော အလိုအလျောက်မောင်းနှင်မှု နှင့် အမြင်အာရုံသက်သက်ဖြင့် အလိုအလျောက်မောင်းနှင်မှုတို့အကြား မလိုအပ်သော ချိတ်ဆက်မှု မရှိပါ။ end-to-end စနစ်သည် မော်ဒယ်ကြီးများဖြင့် မောင်းနှင်ရန် မလိုအပ်ဘဲ၊ ၎င်းကို သန့်ရှင်းသော အမြင်ဖြင့် မောင်းနှင်ရန် မလိုအပ်ပါ။ ၏
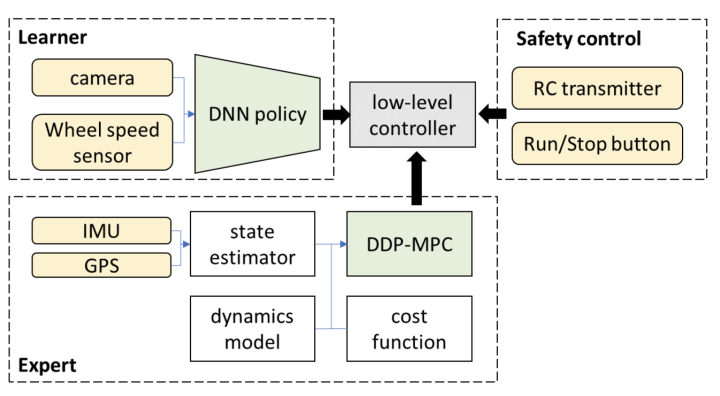
3. ရေရှည်တွင်၊ အထက်ဖော်ပြပါ အဆုံးမှ အဆုံးစနစ်သည် L3 အဆင့်အထက်တွင် အလိုအလျောက် မောင်းနှင်နိုင်စေရန် ကျဉ်းမြောင်းသော အဓိပ္ပာယ်ဖြင့် ဖြစ်နိုင်ပါသလား။
လက်ရှိတွင် pure end-to-end FSD ဟုခေါ်သော စွမ်းဆောင်ရည်သည် L3 အဆင့်တွင် လိုအပ်သော ယုံကြည်စိတ်ချရမှုနှင့် တည်ငြိမ်မှုတို့ကို ပြည့်မီရန် လုံလောက်မှု မရှိပေ။ ပြတ်ပြတ်သားသားပြောရလျှင် မောင်းသူမဲ့စနစ်သည် လူအများလက်ခံလိုလျှင် သော့ချက်မှာ အချို့ကိစ္စများတွင် စက်သည် အမှားလုပ်မိမည်ကို လူအများက လက်ခံနိုင်မလား၊ လူသားများက ၎င်းတို့ကို လွယ်ကူစွာ ဖြေရှင်းနိုင်မလား။ သန့်ရှင်းသော အဆုံးမှ အဆုံး စနစ်အတွက် ပိုခက်ခဲသည်။
ဥပမာအားဖြင့်၊ မြောက်အမေရိကရှိ Waymo နှင့် Cruise နှစ်ခုစလုံးသည် မတော်တဆမှုများစွာရှိခဲ့သည်။ သို့သော်၊ Cruise ၏နောက်ဆုံးမတော်တဆမှုမှာ ဒဏ်ရာရသူနှစ်ဦးရှိခဲ့သော်လည်း ထိုမတော်တဆမှုသည် လူသားယာဉ်မောင်းများအတွက် ရှောင်လွှဲ၍မရလောက်အောင် လက်ခံနိုင်ဖွယ်ရှိသည်။ သို့သော်လည်း ဤမတော်တဆမှုအပြီးတွင်၊ စနစ်သည် မတော်တဆမှု၏တည်နေရာနှင့် ဒဏ်ရာရသူ၏တည်နေရာကို လွဲမှားစေခဲ့ပြီး ဒဏ်ရာရသူများကို အချိန်အတော်ကြာ ဆွဲငင်ခံရစေရန်အတွက် ဆွဲငင်မှုမုဒ်သို့ အဆင့်မြှင့်တင်ခဲ့သည်။ ဤအပြုအမူသည် သာမန်လူသားယာဉ်မောင်းတိုင်း လက်ခံနိုင်စရာမရှိပါ။ ပြီးမြောက်မည်မဟုတ်ပါ၊ ရလဒ်များအလွန်ဆိုးရွားလိမ့်မည်။
ထို့အပြင်၊ ဤသည်မှာ ကျွန်ုပ်တို့သည် အလိုအလျောက်မောင်းနှင်သည့်စနစ်များ ဖွံ့ဖြိုးတိုးတက်မှုနှင့် လုပ်ဆောင်မှုအတွင်း ဤအခြေအနေကို မည်သို့ရှောင်ရှားရမည်ကို ဂရုတစိုက်စဉ်းစားသင့်သည့်နှိုးဆော်ချက်ဖြစ်သည်။
4.ဒါဆို အခုလောလောဆယ်မှာ အမြောက်အများထုတ်လုပ်ထားတဲ့ အထောက်အကူပြုမောင်းနှင်မှုစနစ်တွေရဲ့ နောက်မျိုးဆက်တွေအတွက် လက်တွေ့ကျတဲ့အဖြေတွေက ဘာတွေလဲ။
ကျွန်ုပ်၏လက်ရှိနားလည်မှုအရ၊ မောင်းနှင်မှုတွင် အဆုံးမှအဆုံးပုံစံဟုခေါ်သော လမ်းစဉ်ကိုထုတ်ပြီးနောက်၊ ၎င်းသည် ရိုးရာနည်းလမ်းများအပေါ်အခြေခံ၍ အဖြေတစ်ခုပြန်လာမည်ဖြစ်သည်။ တနည်းအားဖြင့်၊ သင်ယူမှုအခြေခံသည့် အစီအစဉ်ရေးဆွဲသူများနှင့် ရိုးရာလမ်းစဉ်ရေးဆွဲခြင်းဆိုင်ရာ အယ်လဂိုရီသမ်များသည် လမ်းကြောင်းများစွာကို တစ်ပြိုင်နက်တည်း ထုတ်ပေးပြီးနောက် ရွေးချယ်ကိရိယာတစ်ခုမှတစ်ဆင့် လမ်းကြောင်းတစ်ခုအား ရွေးချယ်ပါ။
ဤစနစ်တည်ဆောက်ပုံကို လက်ခံကျင့်သုံးပါက ဤလျှို့ဝှက်ဖြေရှင်းချက်နှင့် ရွေးချယ်မှုမျိုးသည် ဤ Cascade စနစ်၏ စွမ်းဆောင်ရည်အပေါ် ကန့်သတ်ချက်ကို ကန့်သတ်ထားသည်။ ဤနည်းလမ်းသည် မှန်ကန်သော တုံ့ပြန်ချက်သင်ယူမှုအပေါ် အခြေခံနေသေးပါက၊ ကြိုတင်မှန်းဆ၍မရသော ကျရှုံးမှုများ ဖြစ်ပေါ်လာမည်ဖြစ်ပြီး ဘေးကင်းခြင်း၏ ပန်းတိုင်ကို လုံးဝမအောင်မြင်နိုင်ပါ။
ဤအထွက်လမ်းကြောင်းပေါ်ရှိ ရိုးရာအစီအစဥ်ရေးဆွဲခြင်းနည်းလမ်းများကို အသုံးပြု၍ ပြန်လည်ကောင်းမွန်အောင်ပြုလုပ်ခြင်း သို့မဟုတ် ရွေးချယ်ခြင်းအား ကျွန်ုပ်တို့စဉ်းစားပါက၊ ၎င်းသည် သင်ယူမှုစနစ်မှ ထုတ်လုပ်သည့် လမ်းကြောင်းနှင့် ညီမျှသည်။ ထို့ကြောင့်၊ ကျွန်ုပ်တို့သည် ဤလမ်းကြောင်းကို အဘယ်ကြောင့် တိုက်ရိုက် ပိုမိုကောင်းမွန်အောင် မရှာဖွေကြသနည်း။
ဟုတ်ပါတယ်၊ ဤကဲ့သို့ ပိုမိုကောင်းမွန်အောင်ပြုလုပ်ခြင်း သို့မဟုတ် ရှာဖွေမှုပြဿနာသည် ခုံးမဟုတ်၊ ကြီးမားသော နေရာလွတ်တစ်ခုရှိပြီး ကားတွင်းစနစ်တွင် အချိန်နှင့်တစ်ပြေးညီ လုပ်ဆောင်ရန် မဖြစ်နိုင်ကြောင်း အချို့သောလူများက ပြောကြပေမည်။ ဤမေးခွန်းကို သေချာစဉ်းစားရန်လူတိုင်းကို ကျွန်ုပ်တောင်းဆိုပါသည်- လွန်ခဲ့သော ဆယ်နှစ်အတွင်း၊ ခံယူချက်စနစ်သည် အနည်းဆုံး ကွန်ပြူတာ ပါဝါဂွင်အား အဆတစ်ရာ ရရှိခဲ့သော်လည်း ကျွန်ုပ်တို့၏ PnC module ကော မည်သို့နည်း။
မကြာသေးမီနှစ်များအတွင်း အဆင့်မြင့် optimization algorithms များတွင် တိုးတက်မှုအချို့နှင့် ပေါင်းစပ်ထားသော PnC module ကို ကြီးမားသော ကွန်ပြူတာစွမ်းအားကို အသုံးပြုခွင့်ပေးပါက၊ ဤကောက်ချက်သည် မှန်ကန်နေသေးပါသလား။ ဤပြဿနာမျိုးအတွက် ကျွန်ုပ်တို့သည် ပထမအခြေခံမူများမှ မှန်ကန်သောအရာကို သုံးသပ်သင့်သည်။
5. Data-driven နှင့် သမားရိုးကျနည်းလမ်းများကြား ဆက်ဆံရေးကို မည်သို့ပြန်လည်ညှိနှိုင်းမည်နည်း။
စစ်တုရင်ကစားခြင်းသည် အလိုအလျောက်မောင်းနှင်ခြင်းနှင့် အလွန်ဆင်တူသော ဥပမာတစ်ခုဖြစ်သည်။ ယခုနှစ် ဖေဖော်ဝါရီလတွင် Deepmind သည် "Grandmaster-Level Chess Without Search" ဟုခေါ်သော ဆောင်းပါးတစ်ပုဒ်ကို ထုတ်ဝေခဲ့ပြီး AlphaGo နှင့် AlphaZero တို့တွင် ဒေတာမောင်းနှင်မှုကိုသာ အသုံးပြုရန်နှင့် MCTS ရှာဖွေမှုကို စွန့်လွှတ်ရန် ဖြစ်နိုင်ချေရှိမရှိ ဆွေးနွေးထားသည်။ အလိုအလျောက်မောင်းနှင်ခြင်းကဲ့သို့ပင်၊ လုပ်ဆောင်ချက်များကို တိုက်ရိုက်ထုတ်ပေးရန်အတွက် ကွန်ရက်တစ်ခုတည်းကိုသာ အသုံးပြုပြီး နောက်ဆက်တွဲအဆင့်များအားလုံးကို လျစ်လျူရှုထားသည်။
ဒေတာနှင့် မော်ဒယ်ဘောင်များ အမြောက်အမြားရှိနေသော်လည်း ရှာဖွေမှုမသုံးဘဲ မျှမျှတတ ကျိုးကြောင်းဆီလျော်သော ရလဒ်များကို ရရှိနိုင်ကြောင်း ဆောင်းပါးက နိဂုံးချုပ်ထားသည်။ သို့သော် ရှာဖွေမှုအသုံးပြုသည့် နည်းလမ်းများနှင့် နှိုင်းယှဉ်ပါက သိသာထင်ရှားသော ကွာခြားချက်များရှိပါသည်။ ၎င်းသည် ရှုပ်ထွေးသော ဂိမ်းအချို့ကို ကိုင်တွယ်ဖြေရှင်းရန်အတွက် အထူးသဖြင့် အသုံးဝင်သည်။
အဆင့်ပေါင်းများစွာဂိမ်းများလိုအပ်သည့် ရှုပ်ထွေးသောအခြေအနေများ သို့မဟုတ် ထောင့်ကိစ္စများအတွက်၊ ဤဥပမာသည် သမားရိုးကျအကောင်းဆုံးဖြစ်အောင်ပြုလုပ်ခြင်း သို့မဟုတ် ရှာဖွေမှုအယ်လဂိုရီသမ်များကို လုံးဝစွန့်လွှတ်ရန်ခက်ခဲနေသေးသည်။ AlphaZero ကဲ့သို့သော နည်းပညာအမျိုးမျိုး၏ အားသာချက်များကို ကျိုးကြောင်းဆီလျော်စွာ အသုံးချခြင်းသည် စွမ်းဆောင်ရည်ကို မြှင့်တင်ရန် အကောင်းဆုံးနည်းလမ်းဖြစ်သည်။

6.Traditional method = rule-based if else?
လူတော်တော်များများနဲ့ စကားပြောရင်း ဒီသဘောတရားကို ထပ်ခါထပ်ခါ ပြင်ခဲ့ရတယ်။ ဒေတာသက်သက်မဟုတ်သရွေ့၊ စည်းကမ်းကိုအခြေခံတာမဟုတ်ဘူးလို့ လူတော်တော်များများက ယုံကြည်ကြပါတယ်။ ဥပမာအားဖြင့်၊ စစ်တုရင်တွင်၊ ဖော်မြူလာများနှင့် စစ်တုရင်မှတ်တမ်းများကို အလွတ်ကျက်မှတ်ခြင်းမှာ စည်းကမ်းအခြေခံသော်လည်း AlphaGo နှင့် AlphaZero ကဲ့သို့၊ ၎င်းသည် မော်ဒယ်ကို ပိုမိုကောင်းမွန်အောင်ပြုလုပ်ခြင်းနှင့် ရှာဖွေခြင်းမှတစ်ဆင့် ဆင်ခြင်တုံတရားဖြစ်နိုင်စွမ်းကို ပေးပါသည်။ စည်းမျဥ်းအခြေခံတယ်လို့တော့ မထင်ပါဘူး။
ထို့အတွက်ကြောင့်၊ ကြီးမားသော မော်ဒယ်ကိုယ်တိုင်က လက်ရှိတွင် ပျောက်ဆုံးနေပြီး သုတေသီများသည် CoT ကဲ့သို့သော နည်းလမ်းများဖြင့် သင်ယူမှုဆိုင်ရာ စံနမူနာကို ပံ့ပိုးပေးရန် ကြိုးပမ်းနေကြသည်။ သို့သော်၊ စင်စစ် ဒေတာမောင်းနှင်သော ရုပ်ပုံအသိအမှတ်ပြုမှု လိုအပ်သည့် အလုပ်များနှင့် ရှင်းပြ၍မရသော အကြောင်းပြချက်များ လိုအပ်သည့် အလုပ်များနှင့် မတူဘဲ ကားမောင်းသူ၏ လုပ်ဆောင်ချက်တိုင်းတွင် ပြတ်သားသော မောင်းနှင်အားတစ်ခု ရှိသည်။
သင့်လျော်သော အယ်လဂိုရီသမ်ဗိသုကာဒီဇိုင်းပုံစံအောက်တွင်၊ ဆုံးဖြတ်ချက်လမ်းကြောင်းသည် ပြောင်းလဲနိုင်သောဖြစ်လာပြီး မတူညီသောကိစ္စရပ်များကိုဖြေရှင်းရန် ဘောင်များကို အတင်းဖာထေးခြင်းနှင့် ချိန်ညှိခြင်းထက် သိပ္ပံနည်းကျပန်းတိုင်များ၏ လမ်းညွှန်မှုအောက်တွင် တူညီစွာအကောင်းဆုံးဖြစ်အောင်လုပ်သင့်သည်။ ထိုသို့သောစနစ်သည် သဘာဝအားဖြင့် hard-coded ထူးဆန်းသော စည်းမျဉ်းများ အမျိုးမျိုးမရှိပါ။
နိဂုံး
အတိုချုပ်ပြောရလျှင် အဆုံးမှအဆုံးအထိ အလားအလာရှိသော နည်းပညာလမ်းကြောင်းတစ်ခု ဖြစ်နိုင်သော်လည်း အယူအဆကို မည်ကဲ့သို့အသုံးချမည်ကို သုတေသနပြုရန် ပိုမိုလိုအပ်ပါသည်။ ဒေတာနှင့် မော်ဒယ်ဘောင်များ အများအပြားသည် တစ်ခုတည်းသော မှန်ကန်သော အဖြေမဟုတ်ဟု ကျွန်ုပ်ထင်သည်၊ ကျွန်ုပ်တို့သည် အခြားသူများကို ကျော်လွှားလိုပါက၊ ကျွန်ုပ်တို့ ဆက်လက်၍ ကြိုးစားလုပ်ဆောင်ရမည်ဖြစ်ပါသည်။
ပို့စ်အချိန်- ဧပြီ ၂၄-၂၀၂၄