
Hoe definieer je een end-to-end autonoom aandrijfsysteem?
De meest gebruikelijke definitie is dat een "end-to-end"-systeem een systeem is dat ruwe sensorinformatie invoert en direct variabelen uitvoert die van belang zijn voor de taak. Bij beeldherkenning kan CNN bijvoorbeeld "end-to-end" worden genoemd in vergelijking met de traditionele feature + classifier-methode.
Bij autonome rijtaken worden gegevens van verschillende sensoren (zoals camera's, LiDAR, Radar of IMU...) ingevoerd en worden voertuigbesturingssignalen (zoals gaspedaal of stuurhoek) direct uitgevoerd. Om rekening te houden met de aanpassingsproblemen van verschillende voertuigmodellen, kan de output ook worden afgestemd op het rijtraject van het voertuig.
Op basis van deze basis zijn ook modulaire end-to-end-concepten ontstaan, zoals UniAD, die de prestaties verbeteren door supervisie van relevante tussentaken te introduceren, naast de uiteindelijke uitgangsbesturingssignalen of waypoints. Vanuit een dergelijke enge definitie zou de essentie van end-to-end echter de verliesloze overdracht van sensorische informatie moeten zijn.
Laten we eerst de interfaces tussen detectie- en PnC-modules in niet-end-to-end-systemen bekijken. Meestal detecteren we objecten op de witte lijst (zoals auto's, mensen, enz.) en analyseren en voorspellen we hun eigenschappen. Ook leren we over de statische omgeving (zoals wegenstructuur, snelheidslimieten, verkeerslichten, etc.). Als we gedetailleerder zouden zijn, zouden we ook universele obstakels ontdekken. Kortom, de informatie die door deze percepties wordt gegenereerd, vormt een weergavemodel van complexe rijscènes.
Voor sommige zeer voor de hand liggende scènes kan de huidige expliciete abstractie echter niet volledig de factoren beschrijven die het rijgedrag in de scène beïnvloeden, of zijn de taken die we moeten definiëren te triviaal, en is het moeilijk om alle vereiste taken op te sommen. Daarom bieden end-to-end-systemen een (misschien impliciet) alomvattende weergave in de hoop met deze informatie automatisch en verliesloos op PnC's te kunnen reageren. Naar mijn mening zijn alle systemen die aan deze eis kunnen voldoen gegeneraliseerd end-to-end te noemen.
Wat andere kwesties betreft, zoals sommige optimalisaties van dynamische interactiescenario's, ben ik van mening dat in ieder geval niet alleen end-to-end deze problemen kan oplossen, en dat end-to-end misschien niet de beste oplossing is. Traditionele methoden kunnen deze problemen oplossen, en als de hoeveelheid gegevens groot genoeg is, kan end-to-end uiteraard een betere oplossing bieden.
Enkele misverstanden over end-to-end autonoom rijden
1. Besturingssignalen en waypoints moeten end-to-end worden uitgevoerd.
Als u het eens bent met het brede end-to-end-concept dat hierboven is besproken, is dit probleem gemakkelijk te begrijpen. End-to-end moet de nadruk leggen op de verliesloze overdracht van informatie in plaats van het direct uitvoeren van het taakvolume. Een smalle end-to-end-aanpak zal veel onnodige problemen veroorzaken en veel geheime oplossingen vereisen om de veiligheid te garanderen.
2.Het end-to-end systeem moet gebaseerd zijn op grote modellen of pure visie.
Er is geen noodzakelijk verband tussen end-to-end autonoom rijden, autonoom rijden op grote schaal en puur visueel autonoom rijden, omdat het volledig onafhankelijke concepten zijn; een end-to-end-systeem wordt niet noodzakelijkerwijs aangestuurd door grote modellen, en ook niet noodzakelijkerwijs aangestuurd door pure visie. van.
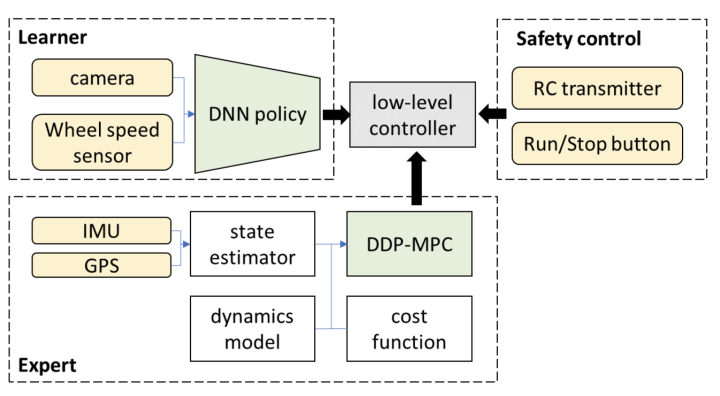
3. Is het met het bovengenoemde end-to-end-systeem in enge zin op de lange termijn mogelijk om autonoom rijden boven het L3-niveau te bereiken?
De prestaties van wat momenteel pure end-to-end FSD wordt genoemd, zijn verre van voldoende om te voldoen aan de betrouwbaarheid en stabiliteit die op L3-niveau vereist zijn. Om het botter te zeggen: als het zelfrijdende systeem door het publiek geaccepteerd wil worden, is de sleutel of het publiek kan accepteren dat de machine in sommige gevallen fouten zal maken en dat mensen deze gemakkelijk kunnen oplossen. Bij een puur end-to-end systeem is dit lastiger.
Zowel Waymo als Cruise in Noord-Amerika hebben bijvoorbeeld veel ongelukken gehad. Het laatste ongeval van Cruise resulteerde echter in twee gewonden, hoewel dergelijke ongevallen tamelijk onvermijdelijk en acceptabel zijn voor menselijke bestuurders. Na dit ongeval heeft het systeem echter de locatie van het ongeval en de locatie van de gewonden verkeerd ingeschat en gedegradeerd naar de pull-over-modus, waardoor de gewonden lange tijd werden voortgesleept. Dit gedrag is voor iedere normale menselijke bestuurder onaanvaardbaar. Dat zal niet gebeuren en de resultaten zullen zeer slecht zijn.
Bovendien is dit een wake-up call dat we zorgvuldig moeten overwegen hoe we deze situatie kunnen vermijden tijdens de ontwikkeling en werking van autonome rijsystemen.
4. Wat zijn op dit moment de praktische oplossingen voor de volgende generatie in massa geproduceerde rij-assistentiesystemen?
Volgens mijn huidige inzichten zal het bij gebruik van het zogenaamde end-to-end-model bij het rijden, na het uitvoeren van het traject, een oplossing opleveren op basis van traditionele methoden. Als alternatief kunnen op leren gebaseerde planners en traditionele trajectplanningsalgoritmen meerdere trajecten tegelijkertijd uitvoeren en vervolgens één traject selecteren via een selector.
Dit soort geheime oplossingen en keuzes beperken de bovengrens van de prestaties van dit cascadesysteem als deze systeemarchitectuur wordt aangenomen. Als deze methode nog steeds gebaseerd is op puur feedbackleren, zullen er onvoorspelbare mislukkingen optreden en zal het doel van veiligheid helemaal niet worden bereikt.
Als we overwegen om dit outputtraject te heroptimaliseren of te selecteren met behulp van traditionele planningsmethoden, is dit gelijkwaardig aan het traject dat wordt geproduceerd door de leergestuurde methode; Waarom optimaliseren en doorzoeken we dit traject daarom niet direct?
Natuurlijk zouden sommige mensen zeggen dat een dergelijk optimalisatie- of zoekprobleem niet-convex is, een grote toestandsruimte heeft en onmogelijk in realtime kan worden uitgevoerd op een systeem in een voertuig. Ik smeek iedereen om deze vraag zorgvuldig te overwegen: in de afgelopen tien jaar heeft het perceptiesysteem minstens honderd keer zoveel rekenkracht ontvangen, maar hoe zit het met onze PnC-module?
Als we ook toestaan dat de PnC-module een grote rekenkracht gebruikt, gecombineerd met enige vooruitgang in geavanceerde optimalisatie-algoritmen van de afgelopen jaren, is deze conclusie dan nog steeds juist? Voor dit soort problemen moeten we overwegen wat vanuit de eerste principes juist is.
5.Hoe verzoen je de relatie tussen datagedreven en traditionele methoden?
Schaken is een voorbeeld dat sterk lijkt op autonoom rijden. In februari van dit jaar publiceerde Deepmind een artikel met de titel "Grandmaster-Level Chess Without Search", waarin werd besproken of het haalbaar is om alleen datagestuurd te gebruiken en MCTS-zoeken in AlphaGo en AlphaZero achterwege te laten. Net als bij autonoom rijden wordt slechts één netwerk gebruikt om acties rechtstreeks uit te voeren, terwijl alle daaropvolgende stappen worden genegeerd.
Het artikel concludeert dat, ondanks aanzienlijke hoeveelheden gegevens en modelparameters, redelijk redelijke resultaten kunnen worden verkregen zonder gebruik te maken van een zoekopdracht. Er zijn echter aanzienlijke verschillen vergeleken met methoden waarbij gebruik wordt gemaakt van zoeken. Dit is vooral handig bij het omgaan met enkele complexe eindspelen.
Voor complexe scenario's of hoekgevallen die games in meerdere stappen vereisen, maakt deze analogie het nog steeds moeilijk om traditionele optimalisatie- of zoekalgoritmen volledig achterwege te laten. Redelijkerwijs gebruik maken van de voordelen van verschillende technologieën zoals AlphaZero is de beste manier om de prestaties te verbeteren.

6.Traditionele methode = op regels gebaseerd, als anders?
Ik heb dit concept keer op keer moeten corrigeren terwijl ik met veel mensen sprak. Veel mensen zijn van mening dat zolang het niet puur datagedreven is, het ook niet op regels gebaseerd is. Bij schaken is het uit het hoofd leren van formules en schaakrecords bijvoorbeeld gebaseerd op regels, maar net als bij AlphaGo en AlphaZero geeft het het model de mogelijkheid om rationeel te zijn door middel van optimalisatie en zoeken. Ik denk niet dat je dit regelgebaseerd kunt noemen.
Hierdoor ontbreekt het grote model zelf momenteel en proberen onderzoekers een leergestuurd model te bieden via methoden zoals CoT. In tegenstelling tot taken die pure datagestuurde beeldherkenning en onverklaarbare redenen vereisen, heeft elke actie van een bestuurder echter een duidelijke drijvende kracht.
Onder het juiste ontwerp van de algoritme-architectuur zou het beslissingstraject variabel moeten worden en uniform geoptimaliseerd moeten worden onder begeleiding van wetenschappelijke doelen, in plaats van met geweld parameters te patchen en aan te passen om verschillende gevallen op te lossen. Zo’n systeem kent uiteraard niet allerlei hardgecodeerde vreemde regels.
Conclusie
Kortom: end-to-end kan technisch gezien een veelbelovende route zijn, maar hoe het concept wordt toegepast vergt meer onderzoek. Ik denk dat een heleboel data- en modelparameters niet de enige juiste oplossing is, en als we anderen willen overtreffen, moeten we hard blijven werken.
Posttijd: 24 april 2024