
Hvordan definere et ende-til-ende autonomt kjøresystem?
Den vanligste definisjonen er at et "ende-til-ende"-system er et system som legger inn rå sensorinformasjon og sender direkte ut variabler som er relevante for oppgaven. For eksempel, i bildegjenkjenning kan CNN kalles "ende-til-ende" sammenlignet med den tradisjonelle funksjonen + klassifiseringsmetoden.
I autonome kjøreoppgaver blir data fra ulike sensorer (som kameraer, LiDAR, Radar eller IMU...) lagt inn, og kjøretøykontrollsignaler (som gass eller rattvinkel) sendes direkte ut. For å vurdere tilpasningsproblemene til forskjellige kjøretøymodeller, kan effekten også lempes til kjøretøyets kjørebane.
Basert på dette grunnlaget har det også dukket opp modulære ende-til-ende-konsepter, som UniAD, som forbedrer ytelsen ved å introdusere overvåking av relevante mellomoppgaver, i tillegg til de endelige utgangskontrollsignalene eller veipunktene. Men fra en så snever definisjon bør essensen av ende-til-ende være tapsfri overføring av sensorisk informasjon.
La oss først se på grensesnittene mellom sensing og PnC-moduler i ikke-ende-til-ende-systemer. Vanligvis oppdager vi hvitelistede objekter (som biler, mennesker osv.) og analyserer og forutsier egenskapene deres. Vi lærer også om det statiske miljøet (som veistruktur, fartsgrenser, trafikklys osv.). Hvis vi var mer detaljerte, ville vi også oppdaget universelle hindringer. Kort sagt, informasjonen fra disse oppfatningene utgjør en visningsmodell av komplekse kjørescener.
Men for noen svært åpenbare scener kan den nåværende eksplisitte abstraksjonen ikke fullt ut beskrive faktorene som påvirker kjøreatferden i scenen, eller oppgavene vi må definere er for trivielle, og det er vanskelig å telle opp alle nødvendige oppgaver. Derfor gir ende-til-ende-systemer en (kanskje implisitt) omfattende representasjon med håp om automatisk og tapsfritt å handle på PnC-er med denne informasjonen. Etter min mening kan alle systemer som kan oppfylle dette kravet kalles generaliserte ende-til-ende.
Når det gjelder andre problemer, for eksempel noen optimaliseringer av dynamiske interaksjonsscenarier, tror jeg at i det minste ikke bare ende-til-ende kan løse disse problemene, og ende-til-ende er kanskje ikke den beste løsningen. Tradisjonelle metoder kan løse disse problemene, og selvfølgelig, når datamengden er stor nok, kan ende-til-ende gi en bedre løsning.
Noen misforståelser om ende-til-ende autonom kjøring
1. Kontrollsignaler og veipunkter må sendes ut for å være ende-til-ende.
Hvis du er enig i det brede ende-til-ende-konseptet som er diskutert ovenfor, er dette problemet lett å forstå. End-to-end bør legge vekt på tapsfri overføring av informasjon i stedet for å sende ut oppgavevolumet direkte. En smal ende-til-ende-tilnærming vil forårsake mye unødvendig trøbbel og kreve mange skjulte løsninger for å ivareta sikkerheten.
2. End-to-end-systemet må være basert på store modeller eller ren visjon.
Det er ingen nødvendig sammenheng mellom ende-til-ende autonom kjøring, autonom kjøring av store modeller og rent visuell autonom kjøring fordi de er helt uavhengige konsepter; et ende-til-ende-system er ikke nødvendigvis drevet av store modeller, og det er heller ikke nødvendigvis drevet av ren visjon. av.
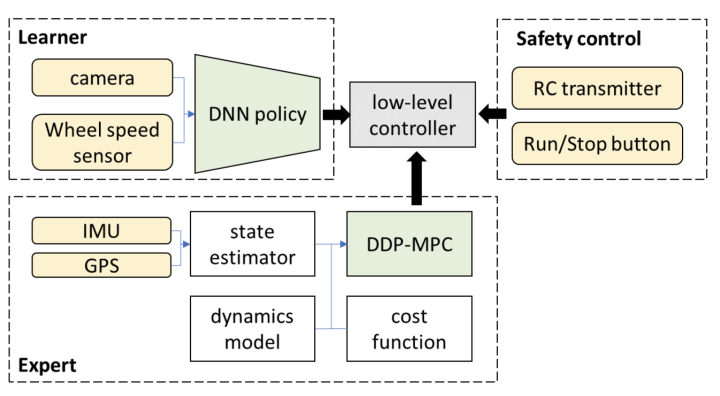
3.I det lange løp, er det mulig for det ovennevnte ende-til-ende-systemet i snever forstand å oppnå autonom kjøring over L3-nivået?
Ytelsen til det som i dag kalles ren ende-til-ende FSD er langt fra tilstrekkelig til å møte påliteligheten og stabiliteten som kreves på L3-nivå. For å si det mer rett ut, hvis det selvkjørende systemet ønsker å bli akseptert av publikum, er nøkkelen om publikum kan akseptere at i noen tilfeller vil maskinen gjøre feil, og mennesker kan enkelt løse dem. Dette er vanskeligere for et rent ende-til-ende-system.
For eksempel har både Waymo og Cruise i Nord-Amerika hatt mange ulykker. Cruises siste ulykke resulterte imidlertid i to skader, selv om slike ulykker er ganske uunngåelige og akseptable for menneskelige sjåfører. Etter denne ulykken feilvurderte systemet imidlertid plasseringen av ulykken og plasseringen av de skadde og nedgraderte til pull-over-modus, noe som førte til at de skadde ble dratt i lang tid. Denne oppførselen er uakseptabel for enhver vanlig menneskelig sjåfør. Det vil ikke bli gjort, og resultatene vil være svært dårlige.
Videre er dette en vekker om at vi bør vurdere nøye hvordan vi kan unngå denne situasjonen under utvikling og drift av autonome kjøresystemer.
4. Så for øyeblikket, hva er de praktiske løsningene for neste generasjon av masseproduserte assisterte kjøresystemer?
Etter min nåværende forståelse, når du bruker den såkalte ende-til-ende-modellen i kjøring, vil den returnere en løsning basert på tradisjonelle metoder etter å ha utgitt banen. Alternativt sender læringsbaserte planleggere og tradisjonelle baneplanleggingsalgoritmer ut flere baner samtidig og velger deretter én bane gjennom en velger.
Denne typen skjulte løsninger og valg begrenser den øvre grensen for ytelsen til dette kaskadesystemet hvis denne systemarkitekturen tas i bruk. Hvis denne metoden fortsatt er basert på ren tilbakemeldingslæring, vil uforutsigbare feil oppstå og målet om å være trygg vil ikke nås i det hele tatt.
Hvis vi vurderer å re-optimalisere eller velge ved bruk av tradisjonelle planleggingsmetoder på denne utdatabanen, tilsvarer dette banen produsert av den læringsdrevne metoden; Derfor, hvorfor optimaliserer og søker vi ikke direkte i denne banen?
Selvfølgelig vil noen si at et slikt optimaliserings- eller søkeproblem er ikke-konveks, har en stor tilstandsplass og er umulig å kjøre i sanntid på et kjøretøysystem. Jeg ber alle om å vurdere dette spørsmålet nøye: I løpet av de siste ti årene har persepsjonssystemet mottatt minst hundre ganger så mye datakraftutbytte, men hva med PnC-modulen vår?
Hvis vi også lar PnC-modulen bruke stor datakraft, kombinert med noen fremskritt innen avanserte optimaliseringsalgoritmer de siste årene, er denne konklusjonen fortsatt riktig? For denne typen problemer bør vi vurdere hva som er riktig fra første prinsipper.
5.Hvordan forene forholdet mellom datadrevne og tradisjonelle metoder?
Å spille sjakk er et eksempel som ligner veldig på autonom kjøring. I februar i år publiserte Deepmind en artikkel kalt "Grandmaster-Level Chess Without Search", som diskuterte om det er mulig å kun bruke datadrevet og forlate MCTS-søk i AlphaGo og AlphaZero. I likhet med autonom kjøring brukes bare ett nettverk til å sende ut handlinger direkte, mens alle påfølgende trinn ignoreres.
Artikkelen konkluderer med at til tross for betydelige mengder data og modellparametere, kan man oppnå rimelige resultater uten å bruke søk. Det er imidlertid betydelige forskjeller sammenlignet med metoder som bruker søk. Dette er spesielt nyttig for å håndtere noen komplekse sluttspill.
For komplekse scenarier eller hjørnesaker som krever flertrinnsspill, gjør denne analogien det fortsatt vanskelig å forlate tradisjonell optimalisering eller søkealgoritmer fullstendig. Rimelig utnyttelse av fordelene ved ulike teknologier som AlphaZero er den beste måten å forbedre ytelsen på.

6.Tradisjonell metode = regelbasert om annet?
Jeg har måttet korrigere dette konseptet om og om igjen mens jeg snakket med mange mennesker. Mange tror at så lenge det ikke er rent datadrevet, er det ikke regelbasert. For eksempel i sjakk er det å huske formler og sjakkrekorder utenat regelbasert, men i likhet med AlphaGo og AlphaZero gir det modellen muligheten til å være rasjonell gjennom optimalisering og søk. Jeg tror ikke det kan kalles regelbasert.
På grunn av dette mangler den store modellen foreløpig, og forskere prøver å gi en læringsdrevet modell gjennom metoder som CoT. Men i motsetning til oppgaver som krever ren datadrevet bildegjenkjenning og uforklarlige årsaker, har hver handling av en person som kjører en klar drivkraft.
Under passende algoritmearkitekturdesign bør beslutningsbanen bli variabel og optimaliseres jevnt under veiledning av vitenskapelige mål, i stedet for å tvinge lappe og justere parametere for å fikse forskjellige tilfeller. Et slikt system har naturligvis ikke alle slags hardkodede merkelige regler.
Konklusjon
Kort sagt kan ende-til-ende være en lovende teknisk rute, men hvordan konseptet brukes krever mer forskning. Jeg tror en haug med data og modellparametere ikke er den eneste riktige løsningen, og skal vi overgå andre, må vi fortsette å jobbe hardt.
Innleggstid: 24. april 2024