
จะกำหนดระบบขับขี่อัตโนมัติแบบ end-to-end ได้อย่างไร?
คำจำกัดความที่พบบ่อยที่สุดคือระบบ "จากต้นทางถึงปลายทาง" คือระบบที่ป้อนข้อมูลเซ็นเซอร์ดิบและส่งออกตัวแปรที่เกี่ยวข้องกับงานโดยตรง ตัวอย่างเช่น ในการจดจำรูปภาพ CNN สามารถเรียกว่า "จากต้นทางถึงปลายทาง" เมื่อเปรียบเทียบกับวิธีฟีเจอร์ + ตัวแยกประเภทแบบดั้งเดิม
ในงานขับขี่อัตโนมัติ ข้อมูลจากเซ็นเซอร์ต่างๆ (เช่น กล้อง, LiDAR, เรดาร์ หรือ IMU...) จะถูกป้อนเข้าไป และสัญญาณควบคุมยานพาหนะ (เช่น คันเร่งหรือมุมพวงมาลัย) จะถูกส่งออกโดยตรง ในการพิจารณาปัญหาด้านการปรับตัวของรถยนต์รุ่นต่างๆ ยังสามารถผ่อนคลายเอาต์พุตให้เหมาะกับวิถีการขับขี่ของยานพาหนะได้
จากรากฐานนี้ แนวคิดแบบ end-to-end แบบโมดูลาร์ก็ได้เกิดขึ้นเช่นกัน เช่น UniAD ซึ่งปรับปรุงประสิทธิภาพโดยแนะนำการควบคุมดูแลงานระดับกลางที่เกี่ยวข้อง นอกเหนือจากสัญญาณควบคุมเอาต์พุตสุดท้ายหรือจุดอ้างอิง อย่างไรก็ตาม จากคำจำกัดความที่แคบดังกล่าว สาระสำคัญของการส่งข้อมูลทางประสาทสัมผัสตั้งแต่ต้นทางถึงปลายทางควรคือการส่งข้อมูลทางประสาทสัมผัสโดยไม่สูญเสียข้อมูล
ก่อนอื่นให้เราตรวจสอบอินเทอร์เฟซระหว่างโมดูลการตรวจจับและ PnC ในระบบที่ไม่ใช่แบบ end-to-end โดยปกติแล้ว เราจะตรวจจับวัตถุที่อยู่ในรายการที่อนุญาตพิเศษ (เช่น รถยนต์ ผู้คน ฯลฯ) และวิเคราะห์และคาดการณ์คุณสมบัติของวัตถุเหล่านั้น นอกจากนี้เรายังเรียนรู้เกี่ยวกับสภาพแวดล้อมที่อยู่นิ่ง (เช่น โครงสร้างถนน การจำกัดความเร็ว สัญญาณไฟจราจร ฯลฯ) หากเรามีรายละเอียดมากกว่านี้ เราก็จะตรวจพบอุปสรรคสากลด้วย กล่าวโดยสรุป ข้อมูลที่ได้จากการรับรู้เหล่านี้ถือเป็นรูปแบบการแสดงฉากการขับขี่ที่ซับซ้อน
อย่างไรก็ตาม สำหรับฉากที่ชัดเจนบางฉาก นามธรรมที่ชัดเจนในปัจจุบันไม่สามารถอธิบายปัจจัยที่ส่งผลต่อพฤติกรรมการขับขี่ในฉากได้ครบถ้วน หรืองานที่เราต้องกำหนดนั้นไม่สำคัญเกินไป และเป็นการยากที่จะระบุงานที่จำเป็นทั้งหมด ดังนั้น ระบบแบบ end-to-end จึงให้การนำเสนอที่ครอบคลุม (อาจโดยนัย) โดยหวังว่าจะดำเนินการกับ PnC ด้วยข้อมูลนี้โดยอัตโนมัติและไม่สูญเสีย ในความคิดของฉัน ระบบทั้งหมดที่สามารถตอบสนองความต้องการนี้สามารถเรียกได้ว่าเป็นระบบ end-to-end ทั่วไป
สำหรับปัญหาอื่นๆ เช่น การเพิ่มประสิทธิภาพบางอย่างของสถานการณ์การโต้ตอบแบบไดนามิก ฉันเชื่อว่าอย่างน้อยไม่เพียงแต่จากต้นทางถึงปลายทางเท่านั้นที่สามารถแก้ปัญหาเหล่านี้ได้ และจากต้นทางถึงปลายทางอาจไม่ใช่ทางออกที่ดีที่สุด วิธีการแบบเดิมสามารถแก้ปัญหาเหล่านี้ได้ และแน่นอนว่า เมื่อปริมาณข้อมูลมีขนาดใหญ่เพียงพอ การเชื่อมโยงจากต้นทางถึงปลายทางอาจให้วิธีแก้ปัญหาที่ดีกว่า
ความเข้าใจผิดบางประการเกี่ยวกับการขับขี่อัตโนมัติแบบ end-to-end
1. สัญญาณควบคุมและจุดอ้างอิงจะต้องส่งออกจากต้นทางถึงปลายทาง
หากคุณเห็นด้วยกับแนวคิดที่ครอบคลุมตั้งแต่ต้นจนจบที่กล่าวถึงข้างต้น ปัญหานี้ก็จะเข้าใจได้ง่าย จากต้นทางถึงปลายทางควรเน้นย้ำถึงการส่งข้อมูลโดยไม่สูญเสียคุณภาพ แทนที่จะส่งออกปริมาณงานโดยตรง แนวทางแบบ end-to-end ที่แคบจะทำให้เกิดปัญหาที่ไม่จำเป็นมากมาย และต้องใช้วิธีแก้ปัญหาที่ซ่อนเร้นมากมายเพื่อความปลอดภัย
2.ระบบ end-to-end จะต้องเป็นไปตามโมเดลขนาดใหญ่หรือวิสัยทัศน์ที่บริสุทธิ์
ไม่มีความเชื่อมโยงที่จำเป็นระหว่างการขับขี่อัตโนมัติแบบ end-to-end การขับขี่แบบอัตโนมัติรุ่นใหญ่ และการขับขี่แบบอัตโนมัติด้วยการมองเห็นล้วนๆ เนื่องจากเป็นแนวคิดที่เป็นอิสระอย่างสมบูรณ์ ระบบแบบ end-to-end ไม่จำเป็นต้องขับเคลื่อนด้วยโมเดลขนาดใหญ่ และไม่จำเป็นต้องขับเคลื่อนด้วยวิสัยทัศน์ที่บริสุทธิ์ ของ.
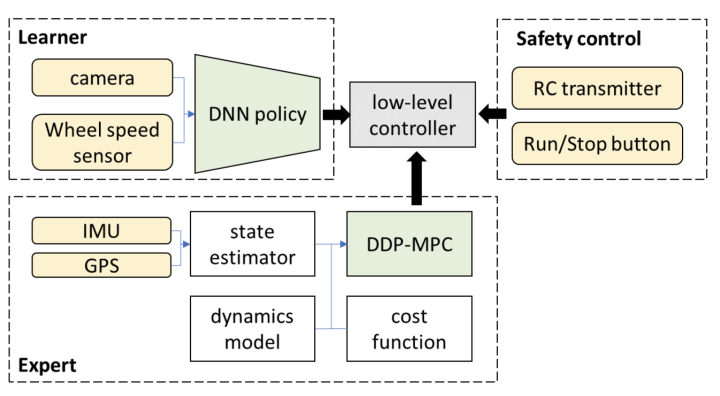
3.ในระยะยาว เป็นไปได้ไหมที่ระบบ end-to-end ที่กล่าวมาข้างต้นในแง่แคบที่จะบรรลุการขับขี่แบบอัตโนมัติเหนือระดับ L3?
ประสิทธิภาพของสิ่งที่เรียกว่า FSD แบบ end-to-end เพียงอย่างเดียวนั้นยังไม่เพียงพอต่อความน่าเชื่อถือและความเสถียรที่ต้องการในระดับ L3 หากจะให้พูดตรงๆ ก็คือ หากระบบขับเคลื่อนอัตโนมัติต้องการให้สาธารณชนยอมรับ สิ่งสำคัญคือประชาชนจะยอมรับได้หรือไม่ว่าในบางกรณี เครื่องจักรจะทำผิดพลาด และมนุษย์ก็สามารถแก้ไขได้อย่างง่ายดาย สิ่งนี้ยากกว่าสำหรับระบบแบบ end-to-end ล้วนๆ
ตัวอย่างเช่น ทั้ง Waymo และ Cruise ในอเมริกาเหนือต่างก็มีอุบัติเหตุหลายครั้ง อย่างไรก็ตาม อุบัติเหตุครั้งสุดท้ายของ Cruise ส่งผลให้มีผู้บาดเจ็บ 2 ราย แม้ว่าอุบัติเหตุดังกล่าวจะค่อนข้างหลีกเลี่ยงไม่ได้และเป็นที่ยอมรับของผู้ขับขี่ อย่างไรก็ตาม หลังจากเกิดอุบัติเหตุครั้งนี้ ระบบจะตัดสินตำแหน่งที่เกิดอุบัติเหตุและสถานที่ของผู้บาดเจ็บผิด และปรับลดระดับเป็นโหมดดึงตัว ทำให้ผู้บาดเจ็บถูกลากเป็นเวลานาน พฤติกรรมนี้เป็นสิ่งที่ผู้ขับขี่ทั่วไปไม่สามารถยอมรับได้ มันจะไม่เสร็จสิ้นและผลลัพธ์จะแย่มาก
นอกจากนี้ นี่เป็นสัญญาณเตือนที่เราควรพิจารณาอย่างรอบคอบว่าจะหลีกเลี่ยงสถานการณ์นี้ได้อย่างไรในระหว่างการพัฒนาและการทำงานของระบบขับขี่อัตโนมัติ
4.ดังนั้น ในขณะนี้ อะไรคือวิธีแก้ปัญหาเชิงปฏิบัติสำหรับระบบช่วยขับขี่ที่ผลิตจำนวนมากรุ่นต่อไป?
ตามความเข้าใจในปัจจุบันของฉัน เมื่อใช้สิ่งที่เรียกว่าแบบจำลอง end-to-end ในการขับขี่ หลังจากแสดงวิถีแล้ว ก็จะส่งคืนวิธีแก้ปัญหาตามวิธีการดั้งเดิม อีกทางหนึ่ง นักวางแผนที่เน้นการเรียนรู้และอัลกอริธึมการวางแผนวิถีแบบดั้งเดิมจะส่งออกวิถีหลายวิถีพร้อมกัน จากนั้นเลือกวิถีหนึ่งวิถีผ่านตัวเลือก
โซลูชันและตัวเลือกแบบซ่อนเร้นประเภทนี้จะจำกัดขีดจำกัดสูงสุดของประสิทธิภาพของระบบคาสเคดนี้ หากใช้สถาปัตยกรรมระบบนี้ หากวิธีนี้ยังคงยึดตามการเรียนรู้แบบตอบรับล้วนๆ ความล้มเหลวที่คาดเดาไม่ได้จะเกิดขึ้นและจะไม่บรรลุเป้าหมายด้านความปลอดภัยเลย
หากเราพิจารณาการปรับให้เหมาะสมอีกครั้งหรือเลือกโดยใช้วิธีการวางแผนแบบดั้งเดิมบนวิถีผลลัพธ์นี้ สิ่งนี้จะเทียบเท่ากับวิถีที่เกิดจากวิธีการขับเคลื่อนการเรียนรู้ ดังนั้น ทำไมเราไม่ปรับให้เหมาะสมและค้นหาวิถีนี้โดยตรง
แน่นอนว่า บางคนอาจบอกว่าปัญหาการปรับให้เหมาะสมหรือการค้นหานั้นไม่นูน มีพื้นที่สถานะขนาดใหญ่ และเป็นไปไม่ได้ที่จะรันแบบเรียลไทม์บนระบบในรถยนต์ ฉันขอร้องให้ทุกคนพิจารณาคำถามนี้อย่างรอบคอบ ในช่วงสิบปีที่ผ่านมา ระบบการรับรู้ได้รับเงินปันผลจากพลังการประมวลผลอย่างน้อยร้อยเท่า แต่โมดูล PnC ของเราล่ะ
หากเราอนุญาตให้โมดูล PnC ใช้พลังการประมวลผลขนาดใหญ่ รวมกับความก้าวหน้าบางอย่างในอัลกอริธึมการปรับให้เหมาะสมขั้นสูงในช่วงไม่กี่ปีที่ผ่านมา ข้อสรุปนี้ยังถูกต้องหรือไม่ สำหรับปัญหาประเภทนี้เราควรพิจารณาสิ่งที่ถูกต้องตั้งแต่หลักแรก
5.จะปรับความสัมพันธ์ระหว่างวิธีที่ขับเคลื่อนด้วยข้อมูลและวิธีการแบบเดิมได้อย่างไร
การเล่นหมากรุกเป็นตัวอย่างที่คล้ายคลึงกับการขับขี่แบบอัตโนมัติมาก ในเดือนกุมภาพันธ์ของปีนี้ Deepmind ตีพิมพ์บทความชื่อ "หมากรุกระดับปรมาจารย์โดยไม่ต้องค้นหา" โดยอภิปรายว่าเป็นไปได้หรือไม่ที่จะใช้เฉพาะข้อมูลที่ขับเคลื่อนด้วยและละทิ้งการค้นหา MCTS ใน AlphaGo และ AlphaZero เช่นเดียวกับการขับขี่อัตโนมัติ มีเพียงเครือข่ายเดียวเท่านั้นที่จะแสดงผลการดำเนินการโดยตรง ในขณะที่ขั้นตอนต่อมาทั้งหมดจะถูกละเว้น
บทความนี้สรุปว่า แม้จะมีข้อมูลและพารามิเตอร์แบบจำลองจำนวนมาก แต่ก็สามารถรับผลลัพธ์ที่สมเหตุสมผลได้โดยไม่ต้องใช้การค้นหา อย่างไรก็ตาม มีความแตกต่างอย่างมีนัยสำคัญเมื่อเปรียบเทียบกับวิธีการที่ใช้การค้นหา สิ่งนี้มีประโยชน์อย่างยิ่งในการจัดการกับการจบเกมที่ซับซ้อน
สำหรับสถานการณ์ที่ซับซ้อนหรือกรณีมุมที่ต้องใช้เกมหลายขั้นตอน การเปรียบเทียบนี้ยังคงทำให้เป็นการยากที่จะละทิ้งการเพิ่มประสิทธิภาพหรืออัลกอริธึมการค้นหาแบบเดิมโดยสิ้นเชิง การใช้ข้อดีของเทคโนโลยีต่างๆ เช่น AlphaZero อย่างสมเหตุสมผลเป็นวิธีที่ดีที่สุดในการปรับปรุงประสิทธิภาพ

6.วิธีดั้งเดิม = อิงกฎถ้ามีอย่างอื่น?
ฉันต้องแก้ไขแนวคิดนี้ซ้ำแล้วซ้ำเล่าในขณะที่พูดคุยกับคนจำนวนมาก หลายๆ คนเชื่อว่าตราบใดที่มันไม่ได้ขับเคลื่อนด้วยข้อมูลเพียงอย่างเดียว มันก็ไม่ได้อิงตามกฎ ตัวอย่างเช่น ในหมากรุก การจำสูตรและบันทึกหมากรุกด้วยการท่องจำนั้นเป็นไปตามกฎ แต่เช่นเดียวกับ AlphaGo และ AlphaZero มันทำให้โมเดลมีความสามารถในการมีเหตุผลผ่านการเพิ่มประสิทธิภาพและการค้นหา ฉันไม่คิดว่ามันจะสามารถเรียกได้ว่าเป็นไปตามกฎเกณฑ์
ด้วยเหตุนี้ โมเดลขนาดใหญ่จึงขาดหายไป และนักวิจัยกำลังพยายามจัดหาโมเดลที่ขับเคลื่อนด้วยการเรียนรู้ผ่านวิธีการต่างๆ เช่น CoT อย่างไรก็ตาม ต่างจากงานที่ต้องใช้การจดจำภาพที่ขับเคลื่อนด้วยข้อมูลล้วนๆ และเหตุผลที่อธิบายไม่ได้ ทุกการกระทำของผู้ขับขี่ล้วนมีพลังขับเคลื่อนที่ชัดเจน
ภายใต้การออกแบบสถาปัตยกรรมอัลกอริทึมที่เหมาะสม วิถีการตัดสินใจควรแปรผันและได้รับการปรับให้เหมาะสมอย่างสม่ำเสมอภายใต้การแนะนำของเป้าหมายทางวิทยาศาสตร์ แทนที่จะบังคับแพตช์และปรับพารามิเตอร์เพื่อแก้ไขกรณีต่างๆ ระบบดังกล่าวโดยธรรมชาติแล้วไม่มีกฎตายตัวแปลกๆ ทุกประเภท
บทสรุป
กล่าวโดยสรุป การเชื่อมโยงจากต้นทางถึงปลายทางอาจเป็นเส้นทางทางเทคนิคที่น่าหวัง แต่วิธีการนำแนวคิดนี้ไปใช้นั้นจำเป็นต้องมีการวิจัยเพิ่มเติม ฉันคิดว่าข้อมูลและพารามิเตอร์โมเดลจำนวนมากไม่ใช่วิธีแก้ปัญหาที่ถูกต้องเท่านั้น และหากเราต้องการเหนือกว่าวิธีอื่นๆ เราต้องทำงานหนักต่อไป
เวลาโพสต์: 24 เมษายน-2024