
آخر سے آخر تک خود مختار ڈرائیونگ سسٹم کی وضاحت کیسے کی جائے؟
سب سے عام تعریف یہ ہے کہ "اختتام سے آخر تک" نظام ایک ایسا نظام ہے جو خام سینسر کی معلومات کو داخل کرتا ہے اور کام کے لیے تشویش کے متغیرات کو براہ راست آؤٹ پٹ کرتا ہے۔ مثال کے طور پر، تصویر کی شناخت میں، روایتی خصوصیت + درجہ بندی کے طریقہ کار کے مقابلے CNN کو "اینڈ ٹو اینڈ" کہا جا سکتا ہے۔
خود مختار ڈرائیونگ کے کاموں میں، مختلف سینسرز (جیسے کیمرے، LiDAR، Radar، یا IMU...) کا ڈیٹا ان پٹ ہوتا ہے، اور گاڑی کے کنٹرول کے سگنلز (جیسے تھروٹل یا اسٹیئرنگ وہیل اینگل) براہ راست آؤٹ پٹ ہوتے ہیں۔ مختلف گاڑیوں کے ماڈلز کے موافقت کے مسائل پر غور کرنے کے لیے، آؤٹ پٹ کو گاڑی کی ڈرائیونگ کی رفتار پر بھی نرم کیا جا سکتا ہے۔
اس بنیاد کی بنیاد پر، ماڈیولر اینڈ ٹو اینڈ تصورات بھی سامنے آئے ہیں، جیسے UniAD، جو حتمی آؤٹ پٹ کنٹرول سگنلز یا وے پوائنٹس کے علاوہ متعلقہ انٹرمیڈیٹ کاموں کی نگرانی متعارف کروا کر کارکردگی کو بہتر بناتے ہیں۔ تاہم، اس طرح کی ایک تنگ تعریف سے، آخر سے آخر تک کا جوہر حسی معلومات کی بے نقصان ترسیل ہونا چاہیے۔
آئیے پہلے نان اینڈ ٹو اینڈ سسٹمز میں سینسنگ اور پی این سی ماڈیولز کے درمیان انٹرفیس کا جائزہ لیں۔ عام طور پر، ہم وائٹ لسٹ کردہ اشیاء (جیسے کاریں، لوگ، وغیرہ) کا پتہ لگاتے ہیں اور ان کی خصوصیات کا تجزیہ اور پیش گوئی کرتے ہیں۔ ہم جامد ماحول (جیسے سڑک کی ساخت، رفتار کی حد، ٹریفک لائٹس وغیرہ) کے بارے میں بھی سیکھتے ہیں۔ اگر ہم مزید تفصیلی تھے، تو ہم عالمگیر رکاوٹوں کا بھی پتہ لگائیں گے۔ مختصراً، ان تصورات کے ذریعے معلومات کی پیداوار پیچیدہ ڈرائیونگ مناظر کا ڈسپلے ماڈل بناتی ہے۔
تاہم، کچھ انتہائی واضح مناظر کے لیے، موجودہ واضح تجرید ان عوامل کو مکمل طور پر بیان نہیں کر سکتا جو منظر میں ڈرائیونگ کے رویے کو متاثر کرتے ہیں، یا جن کاموں کی ہمیں وضاحت کرنے کی ضرورت ہے وہ بہت معمولی ہیں، اور تمام مطلوبہ کاموں کو شمار کرنا مشکل ہے۔ اس لیے، اینڈ ٹو اینڈ سسٹمز اس معلومات کے ساتھ PnCs پر خود بخود اور بغیر کسی نقصان کے عمل کرنے کی امید کے ساتھ (شاید واضح طور پر) جامع نمائندگی فراہم کرتے ہیں۔ میری رائے میں، تمام سسٹمز جو اس ضرورت کو پورا کر سکتے ہیں، کو جنرلائزڈ اینڈ ٹو اینڈ کہا جا سکتا ہے۔
جہاں تک دوسرے مسائل کا تعلق ہے، جیسا کہ متحرک تعامل کے منظرناموں کی کچھ اصلاحیں، میں سمجھتا ہوں کہ کم از کم نہ صرف آخر سے آخر تک ان مسائل کو حل کیا جا سکتا ہے، اور آخر سے آخر تک بہترین حل نہیں ہو سکتا۔ روایتی طریقے ان مسائل کو حل کر سکتے ہیں، اور یقیناً، جب ڈیٹا کی مقدار کافی زیادہ ہو، تو آخر سے آخر تک ایک بہتر حل فراہم کر سکتا ہے۔
آخر سے آخر تک خود مختار ڈرائیونگ کے بارے میں کچھ غلط فہمیاں
1. کنٹرول سگنلز اور وے پوائنٹس کا آؤٹ پٹ ہونا ضروری ہے تاکہ اختتام سے آخر تک ہو۔
اگر آپ اوپر زیر بحث وسیع اینڈ ٹو اینڈ تصور سے اتفاق کرتے ہیں، تو یہ مسئلہ سمجھنا آسان ہے۔ اینڈ ٹو اینڈ کو ٹاسک والیوم کو براہ راست آؤٹ پٹ کرنے کے بجائے معلومات کی بے نقصان ترسیل پر زور دینا چاہیے۔ اختتام سے آخر تک ایک تنگ نقطہ نظر بہت زیادہ غیر ضروری پریشانی کا باعث بنے گا اور حفاظت کو یقینی بنانے کے لیے بہت سے خفیہ حل کی ضرورت ہوگی۔
2. اینڈ ٹو اینڈ سسٹم بڑے ماڈلز یا خالص وژن پر مبنی ہونا چاہیے۔
آخر سے آخر تک خود مختار ڈرائیونگ، بڑے ماڈل کی خود مختار ڈرائیونگ، اور خالصتاً بصری خود مختار ڈرائیونگ کے درمیان کوئی ضروری تعلق نہیں ہے کیونکہ یہ مکمل طور پر آزاد تصورات ہیں۔ ضروری نہیں کہ ایک اینڈ ٹو اینڈ سسٹم بڑے ماڈلز کے ذریعے چلایا جائے، اور نہ ہی یہ ضروری طور پر خالص وژن سے چلتا ہے۔ کی
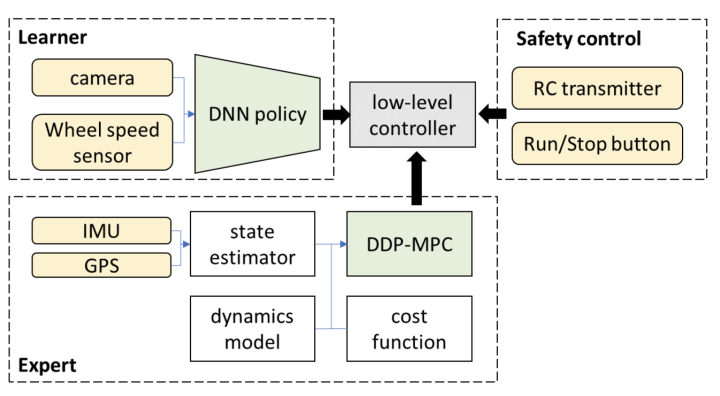
3. طویل مدت میں، کیا اوپر بیان کردہ اینڈ ٹو اینڈ سسٹم کے لیے محدود معنوں میں L3 کی سطح سے اوپر خود مختار ڈرائیونگ حاصل کرنا ممکن ہے؟
اس کی کارکردگی جسے فی الحال خالص آخر سے آخر تک FSD کہا جاتا ہے L3 سطح پر درکار وشوسنییتا اور استحکام کو پورا کرنے کے لیے کافی نہیں ہے۔ مزید دو ٹوک الفاظ میں، اگر سیلف ڈرائیونگ سسٹم عوام کی طرف سے قبول کرنا چاہتا ہے تو اہم بات یہ ہے کہ کیا عوام اس بات کو قبول کر سکتے ہیں کہ بعض صورتوں میں، مشین غلطیاں کرے گی، اور انسان انہیں آسانی سے حل کر سکتے ہیں۔ یہ ایک خالص آخر سے آخر تک کے نظام کے لیے زیادہ مشکل ہے۔
مثال کے طور پر، شمالی امریکہ میں Waymo اور Cruise دونوں کو بہت سے حادثات ہوئے ہیں۔ تاہم، کروز کے آخری حادثے کے نتیجے میں دو افراد زخمی ہوئے، حالانکہ ایسے حادثات کافی حد تک ناگزیر اور انسانی ڈرائیوروں کے لیے قابل قبول ہیں۔ تاہم اس حادثے کے بعد سسٹم نے حادثے کی جگہ اور زخمیوں کی جگہ کا غلط اندازہ لگایا اور پل اوور موڈ میں نیچے کر دیا جس کی وجہ سے زخمیوں کو کافی دیر تک گھسیٹنا پڑا۔ یہ رویہ کسی بھی عام انسانی ڈرائیور کے لیے ناقابل قبول ہے۔ ایسا نہیں کیا جائے گا، اور نتائج بہت برے ہوں گے۔
مزید برآں، یہ ایک ویک اپ کال ہے جس پر ہمیں احتیاط سے غور کرنا چاہیے کہ خود مختار ڈرائیونگ سسٹم کی ترقی اور آپریشن کے دوران اس صورتحال سے کیسے بچا جائے۔
4. تو اس وقت، بڑے پیمانے پر تیار کردہ معاون ڈرائیونگ سسٹمز کی اگلی نسل کے لیے عملی حل کیا ہیں؟
میری موجودہ سمجھ کے مطابق، ڈرائیونگ میں نام نہاد اینڈ ٹو اینڈ ماڈل کا استعمال کرتے وقت، رفتار کو آؤٹ پٹ کرنے کے بعد، یہ روایتی طریقوں پر مبنی حل واپس کرے گا۔ متبادل کے طور پر، سیکھنے پر مبنی منصوبہ ساز اور روایتی ٹریجیکٹری پلاننگ الگورتھم بیک وقت متعدد ٹریجیکٹریز کو آؤٹ پٹ کرتے ہیں اور پھر سلیکٹر کے ذریعے ایک رفتار کو منتخب کرتے ہیں۔
اس قسم کا خفیہ حل اور انتخاب اس جھرن کے نظام کی کارکردگی کی بالائی حد کو محدود کرتا ہے اگر اس نظام کے فن تعمیر کو اپنایا جائے۔ اگر یہ طریقہ اب بھی خالص فیڈ بیک سیکھنے پر مبنی ہے، تو غیر متوقع ناکامیاں واقع ہوں گی اور محفوظ رہنے کا مقصد بالکل بھی حاصل نہیں ہوگا۔
اگر ہم اس آؤٹ پٹ ٹریکٹری پر روایتی منصوبہ بندی کے طریقوں کو استعمال کرتے ہوئے دوبارہ بہتر بنانے یا منتخب کرنے پر غور کرتے ہیں، تو یہ سیکھنے سے چلنے والے طریقہ کے ذریعہ تیار کردہ رفتار کے برابر ہے۔ لہذا، کیوں نہ ہم اس رفتار کو براہ راست بہتر بنائیں اور تلاش کریں؟
بلاشبہ، کچھ لوگ کہیں گے کہ اس طرح کی اصلاح یا تلاش کا مسئلہ غیر محدب ہے، ریاست کی ایک بڑی جگہ ہے، اور گاڑی میں موجود نظام پر حقیقی وقت میں چلنا ناممکن ہے۔ میں ہر ایک سے اس سوال پر غور کرنے کی التجا کرتا ہوں: پچھلے دس سالوں میں، پرسیپشن سسٹم کو کمپیوٹنگ پاور ڈیویڈنڈ سے کم از کم سو گنا ملا ہے، لیکن ہمارے PnC ماڈیول کا کیا ہوگا؟
اگر ہم PnC ماڈیول کو حالیہ برسوں میں ایڈوانسڈ آپٹیمائزیشن الگورتھم میں کچھ پیشرفت کے ساتھ مل کر بڑی کمپیوٹنگ پاور استعمال کرنے کی اجازت دیتے ہیں، تو کیا یہ نتیجہ اب بھی درست ہے؟ اس قسم کے مسئلے کے لیے ہمیں غور کرنا چاہیے کہ پہلے اصولوں سے کیا صحیح ہے۔
5. ڈیٹا پر مبنی اور روایتی طریقوں کے درمیان تعلق کو کیسے ملایا جائے؟
شطرنج کھیلنا خود مختار ڈرائیونگ کی طرح ایک مثال ہے۔ اس سال فروری میں، ڈیپ مائنڈ نے "Grandmaster-Level Chess Without Search" کے نام سے ایک مضمون شائع کیا، جس میں اس بات پر بحث کی گئی کہ آیا AlphaGo اور AlphaZero میں صرف ڈیٹا سے چلنے والا استعمال کرنا اور MCTS تلاش کو ترک کرنا ممکن ہے۔ خود مختار ڈرائیونگ کی طرح، صرف ایک نیٹ ورک کو براہ راست آؤٹ پٹ ایکشنز کے لیے استعمال کیا جاتا ہے، جبکہ اس کے بعد کے تمام اقدامات کو نظر انداز کر دیا جاتا ہے۔
مضمون میں یہ نتیجہ اخذ کیا گیا ہے کہ کافی مقدار میں ڈیٹا اور ماڈل پیرامیٹرز کے باوجود، تلاش کا استعمال کیے بغیر کافی معقول نتائج حاصل کیے جا سکتے ہیں۔ تاہم، تلاش کا استعمال کرتے ہوئے طریقوں کے مقابلے میں نمایاں فرق موجود ہیں۔ یہ خاص طور پر کچھ پیچیدہ اینڈ گیمز سے نمٹنے کے لیے مفید ہے۔
پیچیدہ منظرناموں یا کارنر کیسز کے لیے جن کے لیے ملٹی سٹیپ گیمز کی ضرورت ہوتی ہے، یہ مشابہت اب بھی روایتی اصلاح یا تلاش کے الگورتھم کو مکمل طور پر ترک کرنا مشکل بنا دیتی ہے۔ AlphaZero جیسی مختلف ٹیکنالوجیز کے فوائد کو معقول طور پر استعمال کرنا کارکردگی کو بہتر بنانے کا بہترین طریقہ ہے۔

6. روایتی طریقہ = اصول پر مبنی اگر اور؟
مجھے بہت سے لوگوں سے بات کرتے ہوئے اس تصور کو بار بار درست کرنا پڑا۔ بہت سے لوگوں کا خیال ہے کہ جب تک یہ خالصتاً ڈیٹا پر مبنی نہیں ہے، یہ اصول پر مبنی نہیں ہے۔ مثال کے طور پر، شطرنج میں، فارمولوں اور شطرنج کے ریکارڈ کو روٹ کے ذریعے یاد کرنا اصول پر مبنی ہے، لیکن AlphaGo اور AlphaZero کی طرح، یہ ماڈل کو اصلاح اور تلاش کے ذریعے عقلی ہونے کی صلاحیت فراہم کرتا ہے۔ میں نہیں سمجھتا کہ اسے اصول پر مبنی کہا جا سکتا ہے۔
اس کی وجہ سے، بڑا ماڈل خود فی الحال غائب ہے، اور محققین CoT جیسے طریقوں کے ذریعے سیکھنے پر مبنی ماڈل فراہم کرنے کی کوشش کر رہے ہیں۔ تاہم، ان کاموں کے برعکس جن کے لیے خالص ڈیٹا سے چلنے والی تصویر کی شناخت اور ناقابل وضاحت وجوہات کی ضرورت ہوتی ہے، ڈرائیونگ کرنے والے شخص کے ہر عمل میں واضح محرک قوت ہوتی ہے۔
مناسب الگورتھم آرکیٹیکچر ڈیزائن کے تحت، فیصلہ کی رفتار متغیر ہونی چاہیے اور مختلف معاملات کو ٹھیک کرنے کے لیے پیرامیٹرز کو زبردستی پیچ اور ایڈجسٹ کرنے کی بجائے سائنسی اہداف کی رہنمائی میں یکساں طور پر بہتر ہونا چاہیے۔ اس طرح کے نظام میں قدرتی طور پر ہر قسم کے سخت کوڈ والے عجیب و غریب اصول نہیں ہوتے۔
نتیجہ
مختصراً، آخر سے آخر تک ایک امید افزا تکنیکی راستہ ہو سکتا ہے، لیکن تصور کو کس طرح لاگو کیا جاتا ہے اس کے لیے مزید تحقیق کی ضرورت ہے۔ میرے خیال میں اعداد و شمار اور ماڈل پیرامیٹرز کا ایک گروپ واحد صحیح حل نہیں ہے، اور اگر ہم دوسروں کو پیچھے چھوڑنا چاہتے ہیں، تو ہمیں سخت محنت کرتے رہنا ہوگا۔
پوسٹ ٹائم: اپریل 24-2024